
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- Object Tracking
- 임계처리
- deep learning
- re-identification
- numpy
- 큐
- 딥러닝
- Object Detection
- 자료구조
- 3D
- 알고리즘
- 논문 구현
- flame
- point cloud
- Knowledge Distillation
- 스택
- Python
- NLP
- OpenCV
- reconstruction
- Deeplearning
- Computer Vision
- 프로그래머스
- cv2
- transformer
- center loss
- Threshold
- 파이썬
- attention
- level2
- Today
- Total
공돌이 공룡의 서재
[논문 리뷰] Swin Transformer 본문
Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
https://arxiv.org/abs/2103.14030
[1] Introduction
Transformer는 NLP에서는 좋은 성능을 갖지만, Visual domain에 적용할 때 왜 어려운가?로 시작하고 있다. 이에 대한 원인으로 2가지를 제시하고 있다.
- scale : NLP에서는 word token을 사용하고, 크기가 고정적이지만, visual element는 스케일에 따라 다양하다. 다양하게 될 때 문제는 attention을 적용할 때 문제가 생긴다는 점이다. 기존 transformer 기반 모델들은 고정적인 크기로 가정하기 때문이다.
- high resolution : image의 경우 224x224 크기 정도만 해도 이미지 안에 갖는 픽셀 수가 매우 많다. 이미지의 해상도가 커질수록 처리할 연산량이 많아지는데, 기존 transformer기반 모델들은 입력 이미지의 해상도에 따른 시간 복잡도가 제곱으로 커진다고 지적하고 있다.
Visual domain 전반적으로 적용할 수 있는, 즉 general purpose backbone 모델로서 swin transformer를 통해 이러한 문제점들을 해결할 수 있다고 한다.
Swin transformer의 가장 큰 특징은 논문 제목에서도 알 수 있듯이 hierarchial 한 구조로 feature들에 대해 학습한다는 점과, shifted window 기법을 사용했다는 것이다. 또한 속도(latency) 면에서도 크게 발전했다는 점이다.
[2] Patch partition & merge
모델의 전체적인 구조에 대해 설명하기 전에 우선은 Swin Transformer에서는 input image를 어떻게 처리하는지를 먼저 알아야 한다.
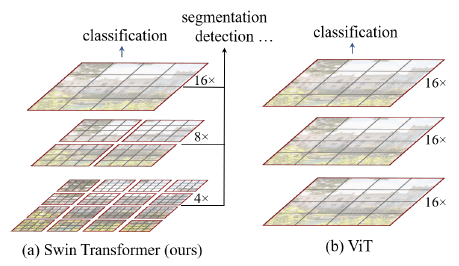
Swin Transformer는 Input image를 patch로 나누고, 네트워크가 깊어질수록 이런 patch들을 합쳐서 사용하는 방식이다. 앞서 리뷰한 ViT에서는 이미지를 고정적인 크기의 패치들로 나누고, 연산 과정에서 patch에 대한 변화는 없었다.
* patch로 나누는 이유는 Transformer에 넣기 위해서 sequence 형태로 만들 필요가 있기 때문이다.
* 둘 다 공통적으로 patch 간 겹치는 영역은 없다.
Swin Transformer에서 사용하는 방식인 patch merge를 자세히 살펴보자. 맨 아래에 있는 layer에서, 한 개의 patch는 4x4 크기의 crop된 image라고 생각해보자. 다음 layer에서는 인접한 2x2개씩 묶어서 (merge) 더 큰 patch를 만든다. 이렇게 되면 patch의 수는 1/4로 줄어들고, patch 해상도 자체는 가로세로로 각각 2배씩 커진다. 이런 방식으로 patch를 점점 merge 해 나간다.
이렇게 merge했을 때 무슨 효과가 있는가? 에 대한 답으로 논문에서는 hierarchial representation을 학습시킬 수 있다고 한다. 이는 FPN 구조나 U-net 같은 모델처럼 다른 해상도에서 얻은 정보들을 같이 고려하는 것과 같은 맥락이라고 한다.
이제 뒤에 모델 구조를 설명하면서 attention에 대해서 설명하면서 더 자세히 알아보겠지만, image resolution이 커지더라도 패치 크기에 대해 linear complexity를 갖는 것도 장점이다. 이전에 있던 transformer 기반 모델들은 image resolution이 커지면 quadratic 하게 증가하기 때문에 큰 차이가 있다.
[3] Model architecture
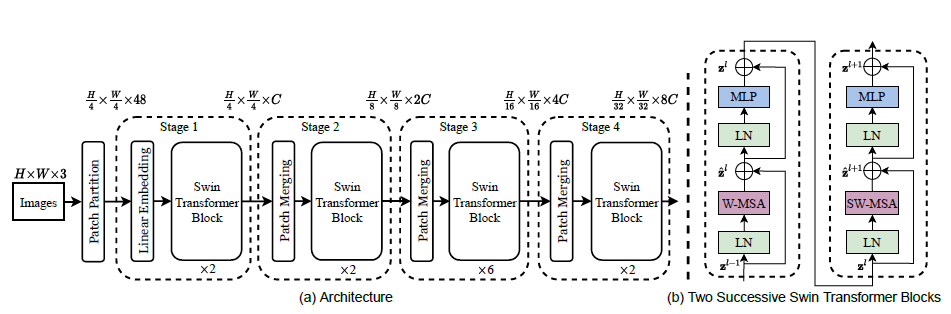
구조 자체는 단순해보이나, 저 Swin transformer block 안에 있는 window self-attention과 shifted window self-attention 원리가 굉장히 어려웠다. 전체적인 관점에서 stage 1부터 설명하면 다음과 같다.
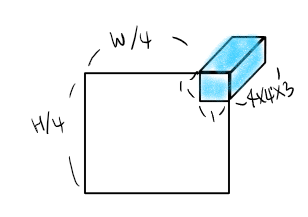
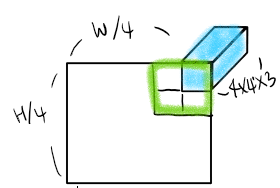
- RGB image를 겹치는 부분이 없도록 patch들로 나눈다. 이때 처음 생성되는 패치는 픽셀을 16개 포함하는, 즉 4x4 크기의 작은 이미지라 볼 수 있다. 한 픽셀당 RGB 값 3개를 갖고 있으므로, 처음 생성되는 패치 하나는 4x4x3 크기라고 할 수 있겠다. 이렇게 나뉜 patch들은 NLP에서 token처럼 고려된다. 패치의 수는 H/4 x W/4 만큼 생기게 된다.
- Linear embedding layer에 이렇게 만든 raw patch들을 통과시킨다. 그러면 한 패치당 4x4 x(C/16) 크기를 갖는다. (channel 차원을 증가시킨다.)
- 이후에 swin transformer을 통과시킨다. 다음 stage에서는 patch들을 2x2개씩 합친다. 그리고 linear embedding layer를 통과시켰을 때, channel 차원을 또 늘린다.
[2] 에서 주어진 이미지를 기반으로 생각해보면
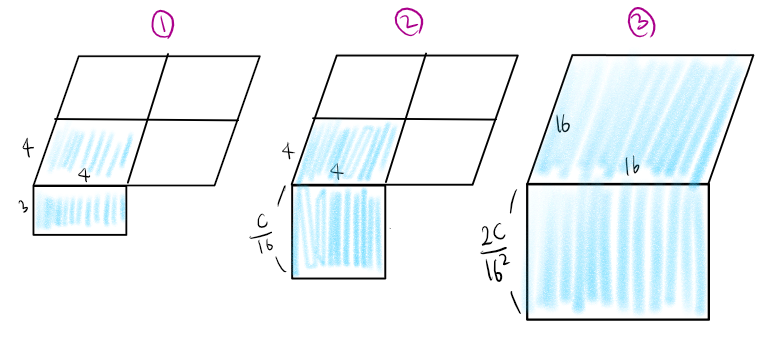
하늘색으로 칠한게 하나의 패치라 치면, 위의 그림과 같은 방식으로 이뤄지는 것이라 생각했다. 그런데 좀만 더 생각해보면 학습시킬 때 Batch도 있고 window 수도 여러 개로 나뉠 텐데 어떻게 self-attention을 적용시키지? 라는 생각이 들었다. official code도 살펴보고 다른 분들 리뷰를 보니 실제로는 위 그림과는 다르게 진행된다.
 |
 |
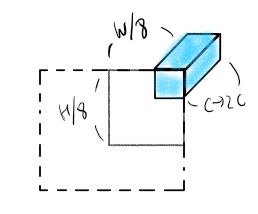 |
모델에서 Window size는 7을 기본값으로 쓰고 있다. 그래서 한 window안에는 저 하늘색 큐브에 해당하는 patch가 7x7개 들어가 있는 것이다.
여기서부터는 핵심 개념 위주로 정리하고 넘어가겠다.
[4] Window based Self-attention
기존의 self-attention을 사용하게 되면, input들에 대해 global하게 본다는 점, 그리고 연산량이 매우 많다는 특징이 있었다. 연산량 문제 때문에, 이와 같은 방식은 Vision에 도입되기에 적절치 않다고 보고 있고, 따라서 7x7(엄밀히는 MxM. M은 window에서 패치를 얼마큼 포함할 것인가에 대한 파라미터) 윈도 안에서 self-attention을 사용하게 된다.
기존의 Multi-head attention은 image resolution이 증가하면 quadratic하게 시간 복잡도가 증가하지만, 이 방법으로는 linear 하게 된다. 따라서 scalable 하다는 점이 강점이다.
[5] Shifted Window Partitioning in Successive blocks
단순하게 위의 방식대로 window안에서만 attention을 하게되면 window 간 connection에 대한 고려가 부족해진다. 이렇게 되면 global 한 특징을 잡아내는 것이 어려워질 것이다. 그래서 어떻게 하면 연산 효율을 유지하면서, window 간 연결을 고려할 수 있을까에 대한 해결책으로 등장한 방법이다.
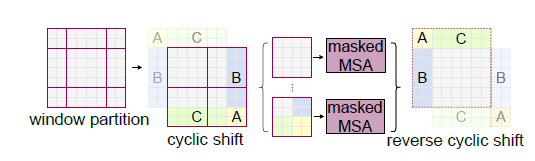
window를 대각선 방향으로 2,2만큼 이동시킨다. 좀 더 직관적으로, 저 partition하는 구분선들은 그대로 둔 다치고, image를 2,2만큼 대각선으로 이동시킨다고 보자. 그러면 오른쪽과 그 아래에 있는 A, B, C들은 구분 선들 바깥으로 빠져나가게 된다. 이 부분들에 대해서는 masking을 처리하고 self-attention을 한다. 이런 방식으로 shift를 계속하고, 다시 원래대로 돌아오게 되는 과정(reverse cyclic shift)을 거친다.
구현된 code에서는 torch.roll()이란 함수를 사용하는데, matrix를 위의 그림처럼 값을 shift시킬 수 있다. 이렇게 했을 때 window의 위치 관계들이 계속 바뀌면서 self-attention을 하기 때문에, global 한 feature도 학습하고 window 간 connection도 고려한다고 볼 수 있을 것이다.
[6] Relative position bias
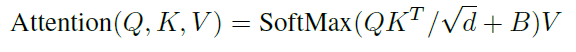
scaled attention score (QK/루트d) 에 relative postion matrix인 B를 더해주고 이후 softmax와 value matrix에 관한 계산을 했더니 absolute position bias(아마 Transformer에서 사용한 sinusoidal wave 값을 넣어주는 것을 말하는듯하다) 보다 더 효과가 좋았다고 설명한다.
[7] Experiment & Conclusion
파라미터 수에 따라서 Swin-transformer T, S, B, L로 나뉜다.
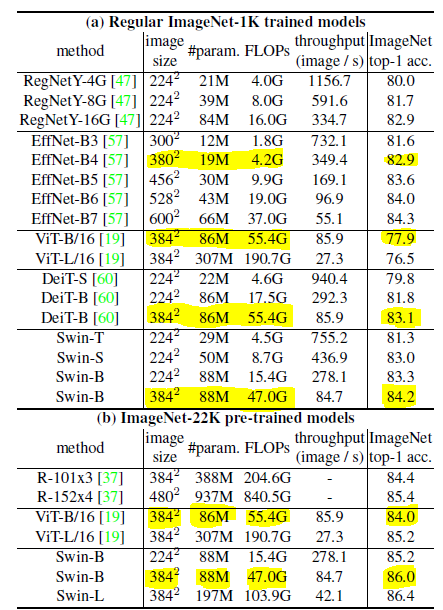
이 표외에도 많은 표가 있지만, 직관적으로 와닿을 것 같아서 골라보았다.
384x384 이미지에 대해서 Swin transformer나 ViT, DeiT 셋 다 파라미터 수는 비슷하지만, FLOPs (처리속도) 면에서 Swin이 더 좋고, 정확도 면에서도 좀 더 높다. EfficientNet은 확실히 파라미터 수가 훨씬 적어서, FLOP도 더 낮다. 그렇지만 Swin이 이보다 더 좋은 정확도를 냈다는 점에서 주목할만하다.
General purpose Transformer model 이 목적인 만큼, official git을 방문해보니 다양한 task에 적용되고, 각 분야에서 굉장히 top-ranking 성능을 보여주고 있었다. 논문 한두번 읽은 것으로는 모델의 detail 한 작동 방식을 다 이해하기는 힘들고, 꼭 코드를 같이 뜯어보면서 봐야 할 모델인 것 같다.
[Reference]
https://visionhong.tistory.com/31
https://byeongjo-kim.tistory.com/36
'딥러닝 > Vision' 카테고리의 다른 글
| [논문 리뷰] DDRNet : Real-time segmentation SOTA (2021.8 기준) (0) | 2021.08.30 |
|---|---|
| [논문 리뷰] YOLO v1 : You Only Look Once (0) | 2021.08.26 |
| [논문 리뷰] DETR: Object Detection with Transformer (0) | 2021.08.24 |
| [논문 리뷰] SFT-GAN : Spatial Feature Transform (0) | 2021.08.20 |
| [논문 리뷰] ViT : Vision Transformer (0) | 2021.08.18 |



