
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- transformer
- 파이썬
- numpy
- center loss
- OpenCV
- Object Detection
- 논문 구현
- attention
- flame
- Threshold
- 프로그래머스
- reconstruction
- 알고리즘
- Object Tracking
- level2
- cv2
- 자료구조
- re-identification
- Deeplearning
- 3D
- deep learning
- 스택
- Python
- 딥러닝
- point cloud
- Knowledge Distillation
- 임계처리
- Computer Vision
- NLP
- 큐
- Today
- Total
공돌이 공룡의 서재
[논문 리뷰] DDRNet : Real-time segmentation SOTA (2021.8 기준) 본문
Deep Dual-resolution Networks for Real-time and Accurate Semantic Segmentation of Road Scenes
https://arxiv.org/pdf/2101.06085v1.pdf
Real-time segmentation에서 SOTA를 차지하고 있는 논문이다.
최근에 하고 있는 프로젝트에서, real-time으로 segmentation을 돌리면 좋을 것 같아서 적절한 모델을 찾아보던 중에 공부하게 되었다. 모델 구성이나 개념적으로 SOTA임에도 크게 어렵지는 않았다.
<1.> Introduction
이전 논문들의 흐름이나, real-time segmentation이 왜 필요한지에 대한 자세한 내용은 생략하겠다. 핵심은 Real-time으로 segmentation을 적용하기 위해선, Inference speed와 정확도 모두 만족스러워야 한다. 특히, 논문에서는 제목에서 보이듯이 자율주행같이 실제 도로에서 쓰일 환경을 염두에 두고 있다.
이 논문에서는 HRNet에 영감을 받아서, deep dual-resolution netowrk를 제안한다. 모델 구조는 밑에서 다시 살펴보겠는데, 간단히 요약하면 branch가 2개인 network다.
Contribution은 다음과 같이 언급하고 있다.
- novel bilateral network : branch가 2개인데 구조상 양측이 서로 영향을 주는 구조다. (독립적 X)
- feature aggregation + pyramid pooling을 섞은 rich context extractor을 디자인했는데, DAPPM이라는 모듈을 말한다.
- Network의 depth와 width를 늘리는 것만으로, mIOU(정확도)와 FPS(처리속도) 사이 top trade-off를 달성했다.
<2.> Related Work
Segmentation task에 있어 지금까지 연구에서 중요하게 여겼던 요소들을 말한다. 첫 번째는 dilated backbone이고 두 번째는 contextual information representation이다. (attention이라고 봐도 되겠다.)
첫 번째 요소에 관해, 유명한 방법들에 대해 아래처럼 소개하고 있는데, 간단하게만 보고 넘어가려 한다.
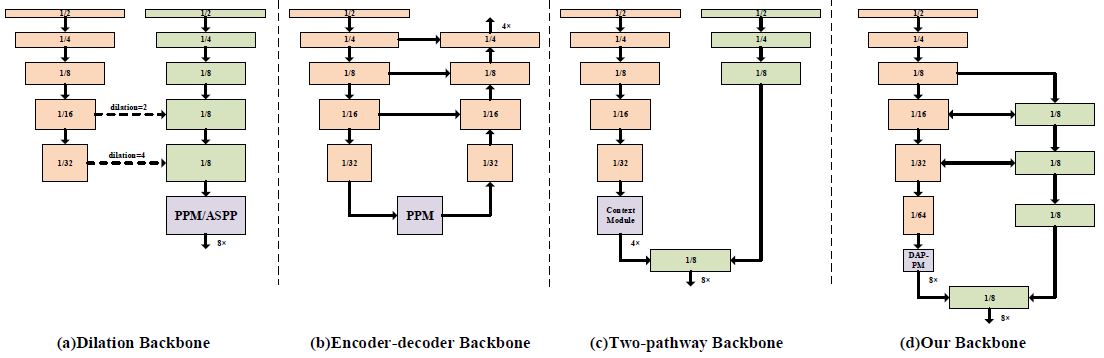
(A) Dilated backbone: DeepLabv3plus에서 upsample 된 feature와 low-level feature를 섞어서 사용했는데, HR representaton의 필요성을 낮출 수 있었다고 한다. Dilated convolution 기반 모델은 feature map의 크기가 계속 작아지기 때문에 정확한 segmentation을 위해서는 HR이 필요한 것 같다. HRNet에 대해서도 언급하는데, 이 모델이 HRNet의 핵심 컨셉을 가져왔다고 한다. 밑에서 HRNet 모델 구조도 간단히 알아볼 것이다.
(B) Encoder-Decoder Backbone (C) Two-path Backbone : 두 모델 모두 (A)보다 파라미터를 덜 쓰고, inference time도 줄이기 위해 제안된 모델들이다.
Contextual model에 대해서도 설명이 나와있는데 결론은 attention module을 사용하지 않고, feature aggregation과 PPM(Pyramid Pooling Module)을 결합한 module을 사용하겠다는 것이다.
<3.> Rethinking HRNet

HRNet은 네트워크 전체적으로 high resolution을 유지하는 모델이다. 네트워크가 깊어질수록, 더 낮은 resolution의 feature map에 대한 branch가 생긴다. branch가 새로 생기는 구간에서 각 branch들끼리 연결된다. 복잡한 구조긴 하지만, object detection에서 FPN-based ResNet 모델들보다 더 좋은 성능을 보여주었다.
논문에서는 semantic segmentation은 high-resolution feautre map과, scene을 잡아낼 수 있는 large receptive field를 필요로 한다고 언급한다. 또한 multi-scale의 경우 object detection에서 좀 더 중요한 요소라 한다. segmentation은 pixel단위로 class를 분류하느 것이 목표고, detection은 다양한 size의 object들을 detect 하는 것이 목표이기 때문이다.
이러한 관점에서, HRNet의 구조를 2개의 branch로 간단하게 할 수 있다고 분석한다. 첫 번째는 high-resolution을 유지하는 feature map이고, 다른 branch는 receptive field를 크게 만드는 branch다.
이렇게 구조를 간단히 함으로써, HRNet보다 더 compact한 model이 되었다. 여러 실험 결과 inference time도 줄고, memory consumption도 줄였다고 한다.
<4.> Dual-resolution Network for Image classification
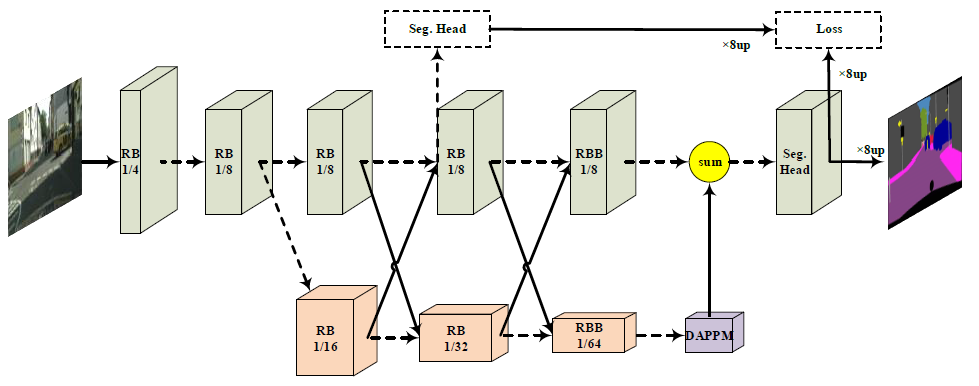
위에서 HRNet의 핵심 개념을 훑어봤는데, DDRNet에서 어떻게 이 개념을 이용했는지 자세히 알아보자. 우선은 ResNet을 backbone이라고 한다. inference speed와 resolution 사이의 trade-off를 고려해서, input image의 1/8이 되는 지점에 branch를 추가한다. (처음부터 2개를 고려한다면 연산 속도가 느려질 것이다.) 이때 추가하는 branch는 down-sampling을 포함하지 않으며, original branch (Resnet 기반 backbone)과 1:1 대응을 갖는다. 이를 통해 high-resolution representation을 학습할 수 있게 된다.
그림 상에서 RB는 residual basic block을 의미하고, RBB는 single residual bottleneck block을 의미한다. 초록색 branch, 즉 feature map resolutio이 변화가 없는 branch가 high resolution을 담당하는 branch다. DAPPM은 뒤에서 알아볼 Deep Aggregation Pyramid Pooling Module이다.
low resolution에 쓰이는 RB같은 경우, 3x3 convolution에 stride 값은 2를 사용했다. high resolution에 쓰이는 block에서는 1x1 convolution을 사용해서 resolution을 유지했다. 마지막 segmentation head 앞에 있는 summation은 pointwise summation을 의미한다.
검은색 화살표로 두 branch의 block들이 서로 연결되어 있다. 이것은 bilateral fusion을 나타낸 것으로, 이 모델에서 중요한 역할을 한다.
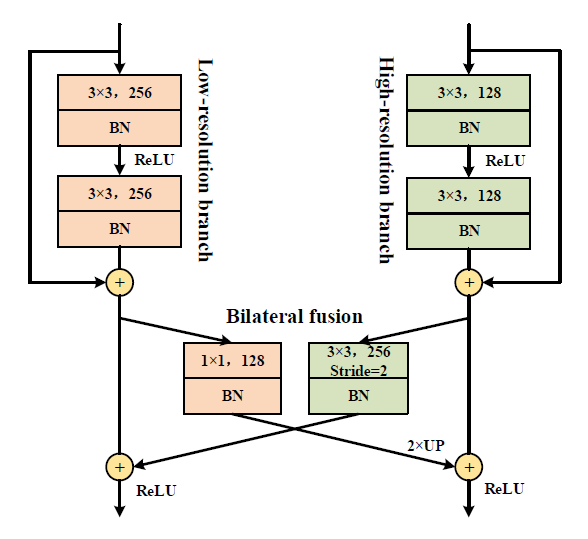
ReLU가 통과되기 전에, high resolution feature의 경우 3x3 convolution에 stride=2인 operation을 해서 크기가 줄어든 feature map을 low resolution branch에 값을 더한다. low resolution feature map의 경우 1x1 convolution을 하고 interpolation을 통해 resolution을 키워서 high-resolution branch에 값을 더해준다.

모델 구조를 보면, 중간에 segmentation head에 대한 auxiliary loss를 추가했다. final loss와 balance를 맞추기 위해 새로 추가한 loss의 weight는 0.4로 설정했다고 한다. 이렇게 auxiliary loss를 추가하는 것은 네트워크가 깊어질 때 효과적이다. back propagation 연산 과정상, 앞쪽 layer의 weight update가 뒤쪽보다 덜 이뤄지는 문제점을 완화해주기 때문이다.
<5.> DAPPM
다음은 이 논문의 contribution 중 하나인 DAPPM에 대해 설명해보려 한다. PPM(Pyramid Pooling Module)은 Pyramid Scene Parsing Network(PSPNet)에서 제안된 모듈이다.

위와 같이 average pooling할 때 여러 해상도에 대해 진행하고, 그 결과들을 upsampling 하여 다음 feature map을 구성한다. 논문에서는 이렇게 single convolution laye들을 사용한 것으로는 충분치 않다고 생각했다. feature aggregation을 결합하여 DAPPM으로 더 발전시켰는데, 아래와 같다.
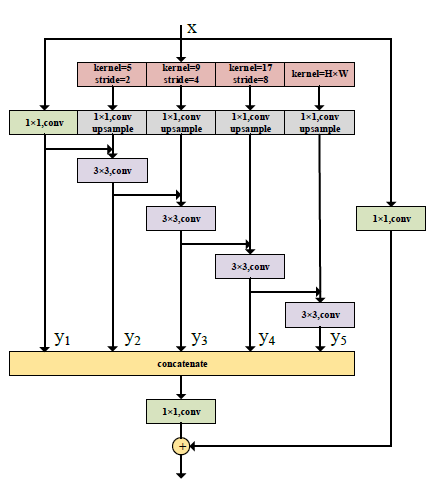
이 구조는 Res2Net에서 아이디어를 얻었다고 적혀있는데, Res2Net은 쓱 훑어보니 아래와 같은 구조를 취하고 있었다.
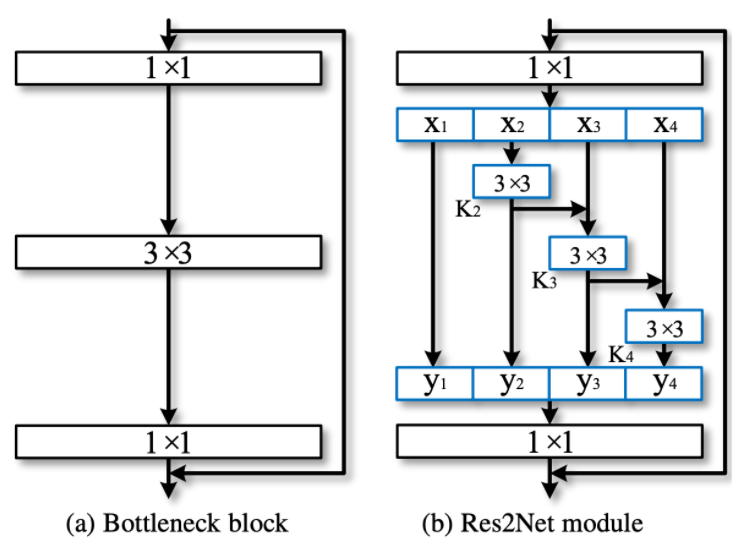
여러 해상도에서 보고, 이들을 hierarchial한 residual way를 사용한 형태다. 이전에 리뷰한 CBAM에서 나온 용어들을 빌리면, cardinality와 depth, width 모두 잘 사용한 구조 같다. 어찌 됐건 이 모듈을 upsampling 형태로 개선했다고 볼 수 있다. PPM을 DAPPM으로 했을 때, 얼핏 보면 연산량이 많이 늘어날 것 같지만 실제로는 1024x1024 input 기준 DAPPM의 input size는 16밖에 안되므로, inference time에 주는 영향이 적다.
<6.> Result
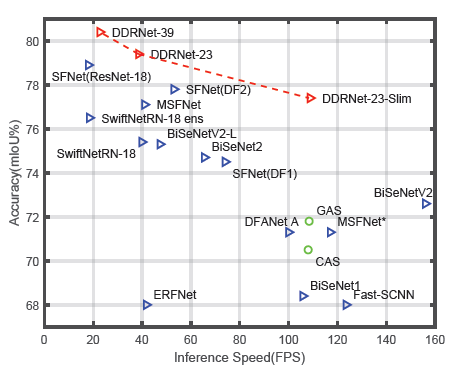
논문 첫 페이지에 있는데 성능을 한 눈에 알기 쉬운 자료다. 모델의 depth, width에 따른 trade-off 또한 확연하게 보인다. DDRNet-39 의 경우 Accuracy에서 SOTA를 차지했다. 23-slim 만해도 정확도와 FPS 모두 매우 높은 면에서 좋은 모델임이 보인다.

PPM과 DAPPM에 대한 비교인데, speed에서 3 정도 손해를 보고 정확도에서 1% 이득을 보았다. 위에서 보았듯이, DAPPM이 상대적으로 복잡한 구조임에도 불구하고 inference time에는 큰 영향이 없었음을 확인할 수 있었다.
'딥러닝 > Vision' 카테고리의 다른 글
| [논문 리뷰] Stacked Hourglass Networks for Human Pose Estimation (0) | 2021.09.28 |
|---|---|
| [논문 리뷰] YOLACT : Real-time instance segmentation (0) | 2021.09.02 |
| [논문 리뷰] YOLO v1 : You Only Look Once (0) | 2021.08.26 |
| [논문 리뷰] DETR: Object Detection with Transformer (0) | 2021.08.24 |
| [논문 리뷰] Swin Transformer (1) | 2021.08.21 |



