
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||
| 5 | 6 | 7 | 8 | 9 | 10 | 11 |
| 12 | 13 | 14 | 15 | 16 | 17 | 18 |
| 19 | 20 | 21 | 22 | 23 | 24 | 25 |
| 26 | 27 | 28 | 29 | 30 | 31 |
- 딥러닝
- 파이썬
- Deeplearning
- 임계처리
- OpenCV
- cv2
- center loss
- Object Detection
- Threshold
- 스택
- Computer Vision
- reconstruction
- NLP
- flame
- level2
- 3D
- 프로그래머스
- 논문 구현
- 큐
- transformer
- re-identification
- attention
- numpy
- Object Tracking
- point cloud
- Python
- Knowledge Distillation
- 자료구조
- deep learning
- 알고리즘
- Today
- Total
공돌이 공룡의 서재
[논문 리뷰] DETR: Object Detection with Transformer 본문
End-to-End Object Detection with Transformers
https://arxiv.org/abs/2005.12872
Transformer를 시작으로 Vision에 적용한 큼지막한 논문들에 대한 리뷰를 하는 중인데, Object detection을 transformer로 해결한 모델에 대해 소개하는 논문이다. 대략적으로 아 이렇구나 수준으로는 쉽게 읽은 논문인데, 자세하게 파악하자니 상당히 어려웠다...
<1.> Introduction
기존에 있던 Faster R-CNN 기반 detection 모델들의 한계를 지적하고 있다. 모델 구조가 Indirect prediction이라서 end-to-end 한 방법이 아니다. 또한 Hand-design 한 요소들이 도입되었는데, 그 예로 anchor box와 non-maximum suppress, 등의 방법이 해당된다.
DETR은 이와는 다르게 direct predicton을 수행하는 모델이라는 점에서 다르다. CNN model - Transformer - FFN 으로 구성되어 있다. 모델 구조에 대해서는 밑에서 자세히 알아보자.
Faster R-CNN 기반 SOTA 모델들과 비교했을 때, 큰 object들에 대해서는 더 좋은 성능을 보여주지만, 작은 object에 대해서는 아직 부족하다고 말한다. 대신에 detection 외의 더 복잡한 task로도 확장이 가능한 것이 장점이다. panoptic segmentation을 그 예로 들고 있다.
<2.> Model architecture
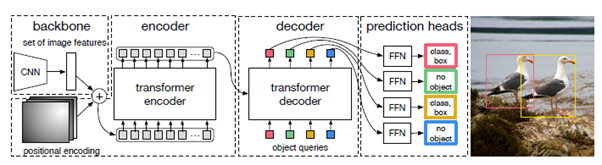
CNN based feature extractor를 이용해서 feature를 뽑고 나면, 1x1 convolution을 통과시켜서 깊이를 낮춘 다음에, 이들을 flatten시켜서 쭉 펼쳐진 값을 position embedding과 합친다. 즉, Transformer encoder는 high-level feature로 이루어진 sequence를 입력으로 받게 되는 것이다.
CNN model의 경우 논문에서는 pretrained ResNet-50이랑 ResNet101을 torchvision에서 가져와서, fine-tuning해서 사용했다고 한다. 논문에서 설명하는 이론상 다른 model을 써도 상관없을 것 같긴 하다.
position embedding의 경우 original Transformer에서 쓰는 sinusoidal wave를 이용한 absolute position embedding을 사용하고 있다. 또한 맨 처음 input에만 들어가는 것은 아니고, 모든 encoder, decoder block에 들어간다. (그림이 좀 헷갈렸는데 논문을 꼼꼼히 읽어보니 그랬다)
Decoder에서는 N개의 object를 병렬로 계산한다는 점에서 기존의 디코더와 차이가 있다. permutation-invariant하다는 특징이 있다. 여기서 N이란 한 이미지 내에 있는 object들의 수보다 큰 값이라고 가정하고 둔다. 논문에서는 100개로 두었다.
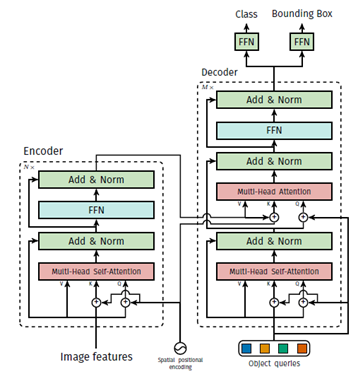
Transformer 모델 구조만 놓고 보면, original Transformer에서는 decoder의 첫 번째 sublayer로 Mask self-attention을 사용했었는데 DETR에서는 self-attention을 사용한다. 대신에 input이 object queries가 들어온다. 또한 encoder의 결과를 key와 value로 사용하는 encoder-decoder attention에서, encoder의 결과를 사용한 key값에도 positional embedding을 한다는 점이 조금씩 다르다.
Decoder가 Permutation invarint란 말에 대해서는 구체적으로 설명이 나와있지 않지만, Transformer나 GPT, XLNet, 등 논문을 읽으면서 공부한 내용을 바탕으로 정리해보면 이렇다. decoder에서 처음에는 mask self-attention을 사용하는데, auto-regressive 성격이 있다. masking 때문에 값들의 순서에 따라서 계산 결과가 달라지기 때문이다. 그러나 self-attention으로 대체하고 나면, 모든 입력들이 다 연결된 상태가 되기 때문에 permutation-invariant 하다고 할 수 있겠다.
이러한 특징때문에 image에서 뽑은 feature들의 위치 관계에 position embedding으로 보충했다고 볼 수 있겠다. 대신에, ViT에서도 보았듯이 global 하게 image를 파악할 수 있다는 장점은 있다.
최종적으로 나온 결과는 N개 query에 대한 값들이 나올텐데, 각각 독립적으로 뒤의 FFN에 의해 box coordinate와 class label로 decode 된다.
<3.> Object Detection sete prediction loss
예측한 값과 ground truth 사이 bipartite matching을 사용하고, loss function은 이 matching이 최적이 되도록 하며, bounding box loss 또한 최적화한다.
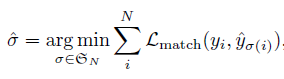
여기서 L_match는 prediction과 ground truth 사이 pair-wise matching cost에 해당한다. N개의 예측들과 ground truth가 어떻게 매칭 되어야 최소가 되는지 그런 매칭을 찾는 과정이라 할 수 있다.
이렇게 cost를 설정하는 것이 region proposal이나 anchor과 같은 역할을 한다고 보고 있다. 다른 점이 있다면 matching을 통해 unique한 결과를 찾게 되므로, non-maximum suppression과 같은 과정이 따로 필요 없다.
이렇게 찾은 모든 pair에 대해 Hungarian loss를 사용한다.
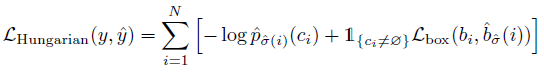
모든 matching에 대한 loss를 사용하면 time complexity가 커서 이 알고리즘을 도입했다고 한다.
bounding box loss로는 IOU(Intersection over Union. 쉽게 말해서 박스끼리 겹치는 영역의 정도)와 L1 loss term(좌표 거리 차이)를 선형적으로 결합해서 사용했다.
<4.> Result
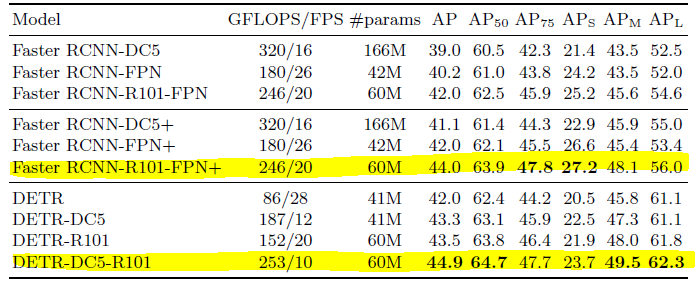
유의미한 비교를 하려면 강조한 두 부분을 보면 될 것 같다. Faster RCNN model은 Detectron2에서 제공하는 model을 쓰되 GIOU를 이용하여 학습한 결과다.
모델의 파라미터 전체 수는 똑같은데, AP값을 확인해보면 대체로 DETR이 더 좋은 성능을 보인다. FPS는 초당 object dection을 수행하는 프레임 수라고 볼 수 있는데, DETR이 Flop이 좀 더 많아서 그런지 오래 걸리긴 한다.
이후에는 experiment에 대한 구체적인 설명들과, panoptic segmentation에도 적용시킨 결과 및 model supplementary에 대한 설명이 이어진다.
* bipartite matching과 hungarian algorithm을 추가로 공부해서 보충해봐야겠다
#TODO:
Object queries 에 대한 내용 보충
'딥러닝 > Vision' 카테고리의 다른 글
| [논문 리뷰] DDRNet : Real-time segmentation SOTA (2021.8 기준) (0) | 2021.08.30 |
|---|---|
| [논문 리뷰] YOLO v1 : You Only Look Once (0) | 2021.08.26 |
| [논문 리뷰] Swin Transformer (1) | 2021.08.21 |
| [논문 리뷰] SFT-GAN : Spatial Feature Transform (0) | 2021.08.20 |
| [논문 리뷰] ViT : Vision Transformer (0) | 2021.08.18 |



