
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- 자료구조
- center loss
- Threshold
- 딥러닝
- point cloud
- cv2
- NLP
- 파이썬
- attention
- level2
- transformer
- 스택
- flame
- Python
- Computer Vision
- 프로그래머스
- numpy
- 임계처리
- Deeplearning
- OpenCV
- deep learning
- Knowledge Distillation
- reconstruction
- Object Detection
- 큐
- 논문 구현
- Object Tracking
- re-identification
- 3D
- 알고리즘
- Today
- Total
공돌이 공룡의 서재
[논문 리뷰] YOLO v1 : You Only Look Once 본문
You Only Look Once: Unified, Real-Time Object Detection
https://arxiv.org/abs/1506.02640
2015년에 나와서 Real-time object detection에서 한 획을 그은 논문이다. 지금은 YoLo v4까지 나온 걸로 알고 있다. v5는 공식 논문이 없다고 한다. EfficientDet까지 다루기 전에 Mask R-CNN이나 다른 YOLO 시리즈도 다뤄보고자 한다.
개인적으로 YOLO에서는 모델 구조보다는 loss metric과 1 stage detection이 어떻게 가능한지가 특히 눈여겨볼 점이라고 생각한다.
<1.> Introduction
사람이 이미지를 인식할 때 어떻게 이뤄지는 서두에 언급하고 있다. 우리는 이미지를 한 번만에 보자마자 자연스럽게 어디에 무엇이 있는지를 인식할 수 있다. 자율주행이나 로보틱스, 등 실생활에서도 object detection이 쓰이려면 real-time 한 algorithm이 필수다. frame 하나당 처리하는 속도가 오래 걸리면 실생활에서 쓰기 힘들기 때문에, 여러 면에서 중요하다.
fast r-cnn과 faster r-cnn의 경우 모델 구조가 복잡하다. (이 당시는 아직 mask r-cnn이 나오기 전이다.) region proposal, non-maximum suppression 등 여러 방법들을 사용하기 때문이다. 이 부분은 전에 리뷰한 DETR 논문에서도 지적한 fast r-cnn 기반 모델의 한계다. 각 개별적인 구성 요소들이 따로 학습이 되어야 한다는 단점 때문에, 최적화하는 과정이 느리고 어렵다.
논문에는 언급되어 있지만 fast r-cnn 기반 모델은 2 stage detector다. region proposal network를 통해 object가 있을법한 영역들을 먼저 찾고 그 영역에 대한 classification을 수행하고 나서, 이후에 bounding box와 classification을 계산하기 때문이다. 이렇게 복잡한 구조다 보니 frame 하나를 처리하는데 속도가 매우 빠르기는 힘들 것이다. 직관적으로 생각했을 때, 사람이 한 번만에 이미지를 인식하는 것이랑도 흐름이 다르다.
그래서 YOLO에서는 detection 문제를 single regression 문제로 해결하고자 한다. 모델 또한 1 stage로 구성했다. region proposal 같은 과정이 없다. 그러다보니 이미지 전체를 놓고 한 번에 통과시키기 때문에, fps가 더 빨라졌다.
*fps = frames per second. 초당 처리하는 frame 수
속도에서는 엄청난 향상을 이뤘지만 아직 정확도에서는 한계가 있다고 지적하고 있다. 이제 구체적으로 살펴보자.
<2.> Unified Detection
YOLO에서는 입력 이미지 전체를 네트워크에 통과시켜서 예측한다. 또한 classification과 bounding box에 대한 예측이 동시에 이뤄진다. 이런 구조덕에, 좋은 성능을 내면서 end-to-end training이 가능한 것이 장점이다.

우선 처음에 입력 이미지를 SxS grid로 나눈다. object의 중심이 grid cell 안에 들어와 있으면, 그 grid는 해당 object를 찾는 것을 담당하게 된다. S는 여기서 7로 설정했다.
각 grid cell은 B개의 bounding box와 이 box들의 confidence score를 예측한다. B는 논문에서 2로 설정했다. 여기서 confidence score란 box가 object를 담고 있는지 없는지, 있다면 얼마나 잘 겹치게 bounding 하고 있는지를 반영한다. 논문에서는 Pr(Object) * IOU(truth|pred)로 정의하고 있다. 만약 box안에 object가 없다면 score는 0이 된다.
* IOU는 Intersection Over Union의 약자로, predicted box와 ground truth 사이의 교집합이다.
각 bounding box는 x,y,w,h와 confidence 값으로 이뤄져 있다. x, y는 box의 중심 좌표, w, h는 box의 각각 가로, 세로 길이다.
또한 각 grid cell은 conditional class probability를 예측한다. 이 때 class는 B 값 (bounding box 수)에 상관없이 하나에 대해서 예측한다. confidence + bounding box와 class probability map 둘을 같이 고려하면, box안에 특정 class가 나타날 확률과 그 box가 object를 얼마나 잘 bounding 하고 있는지를 계산하게 된다고 볼 수 있다.
<3.> Network Design
GoogleNet의 Inception module에 영감을 받았다고 하는데, inception module 대신에 단순하게 1x1 reduction layer를 사용했다. convolution layer가 총 24개가 있고, linear layer는 2개를 사용한다.
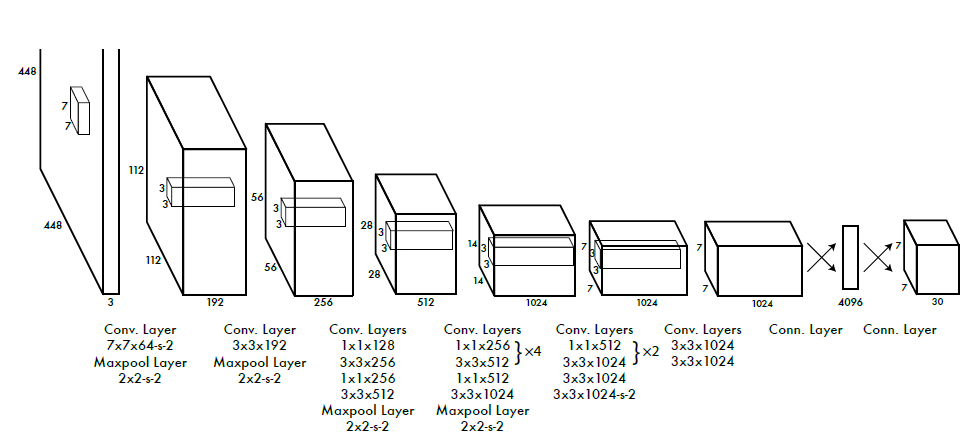
Fast YOLO는 9개의 convolution layer만 사용한 버전이다. accuracy는 조금 포기하되 모델이 더 가벼워지다보니 더 빨라졌다. 최종 결과로는 7x7x30 이 나오게 되는데, 이 30은 2개의 B(B 하나에 5개의 값을 포함)과 20개의 class 분류 결과다.
모델 구조 자체는 크게 어렵지 않다. 각 layer마다 leaky ReLU를 사용했다.
앞에 20개의 convolution layer의 경우 논문에서는 Imagnet으로 pre-train convolution layer들을 가져와서 구성했다고 한다. 이후에 여기에 convolution layer를 4개 붙이고, FCN도 2개 붙여서 위와 같은 최종 구조가 된다.
<4. Loss>
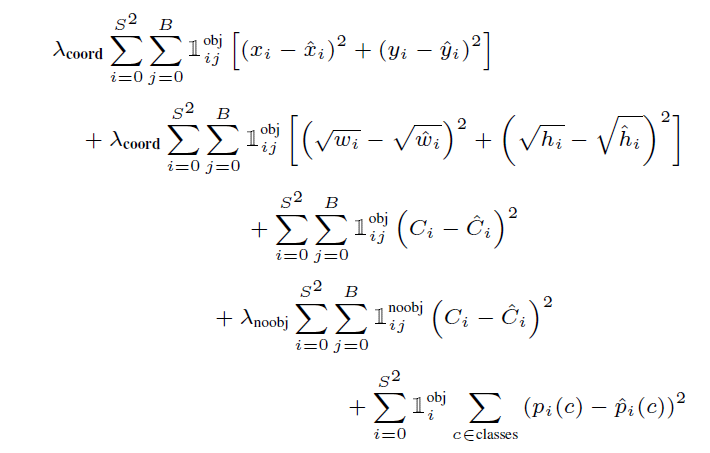
수식이 좀 복잡한데 notation을 먼저 살펴보면, 겹쳐쓴 1의 경우 위에 obj가 적혀 있으면 object가 grid cell안에 있으면 뒤에 나올 term을 계산하고, 아니면 0으로 보겠다는 의미다. 위에 noobj가 적혀 있는 건 그 반대다.
위에 2개를 먼저 살펴보면 박스의 중심 좌표끼리의 거리를 계산하고, 가로 세로 길이 차이에 대해서도 계산한다. 가운데는 confidence score의 차이를 계산한다고 볼 수 있겠다. 계산의 편리성을 위해서 bounding box의 좌표에 대한 loss를 계산할 때 sum-square 방식을 사용했다고 한다. (좌표 값을 단순히 빼고 제곱해서 더하는 것이다.)
4번째 식은 box 안에 obj가 없을 때에 계산되는 term이다. ground truth랑 비교했을 때 box안에 object가 없을 때 predict된 box도 confidence score를 낮춰야 한다. 이에 대한 loss라고 볼 수 있다.
지금까지가 bounding box에 대한 식이라면, 마지막은 class probability map에 대한 loss다. 각 grid마다 object가 있다면 특정 class로 결과가 나올 수 있도록 update를 도와주는 식이다.
식마다 앞에 람다가 붙어있는데 이는 loss term들의 balance를 맞추기 위한 parameter다. 대부분의 grid에 object가 있는 것은 아니기 때문에, 일반적으로 4번째 항의 값이 다른 항들보다 훨씬 클 것으로 예상된다. 앞의 식들은 box안에 object가 있을 때 box의 정확도를 높이기 위한 loss인데 이들에 대한 gradient 계산이 덜 이뤄지게 된다. 이는 곧 성능 저하로 이뤄진다.
따라서 논문에서는 람다_coord를 5, 람다_noobj를 0.5로 설정했다.
confidence score에서 IOU도 사용하니 식이 간단하지는 않다. 복잡한 식이지만 여기서 중요한 점은 class prediction과 bounding box에 대한 loss가 동시에 이뤄지고 있다는 점이다.
<5. Inference>
중요한 점은 속도가 굉장히 빨랐다는 점.
추가로 볼 것이 있다면, grid 경계에 크거나 작은 object들이 있다면 여러 cell들이 detection을 하게 될텐데, 그럼 multiple detection이 발생한다. 이를 다루기 위해 non-maximum suppression을 추가해주면, 정확도가 더 올라간다고 한다.
<6.> YOLO의 한계
첫 번째는 이미지를 단순히 SxS로 나누고 각 grid에 대해서만 처리한다는 점이다. spatial 한 면에서 constraint가 크기 때문에, 작은 object들이 한 grid안에 여러 개 나타난다면 잘 처리하기 힘들다는 점이 제시되고 있다.
위에서 설정한 loss function의 문제는 큰 box들끼리 계산할 때 loss와 작은 box들끼리 계산할때 loss 중 후자가 더 크게 계산된다는 점이다. box가 작을 때 error가 있으면 coordinate 자체는 크게 값이 변하지 않더라도, IOU 때문에 confidence score가 많이 달라지기 때문이다.
따라서 논문에서는 주된 한계점을 incorrcet localization라고 말한다.
<7.> Result
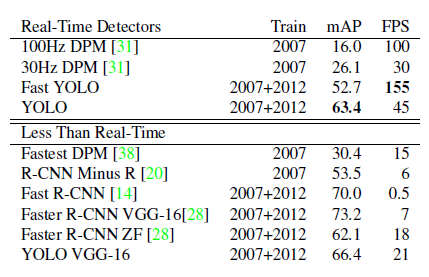
FPS를 보면 초당 처리하는 frame 수가 다른 모델들과 몇 배 차이난다. Fast YOLO로 가면 훨씬 커진다. 정확도에 대해 Trade-Off가 생기는 건 모델의 한계점이다.
'딥러닝 > Vision' 카테고리의 다른 글
| [논문 리뷰] YOLACT : Real-time instance segmentation (0) | 2021.09.02 |
|---|---|
| [논문 리뷰] DDRNet : Real-time segmentation SOTA (2021.8 기준) (0) | 2021.08.30 |
| [논문 리뷰] DETR: Object Detection with Transformer (0) | 2021.08.24 |
| [논문 리뷰] Swin Transformer (1) | 2021.08.21 |
| [논문 리뷰] SFT-GAN : Spatial Feature Transform (0) | 2021.08.20 |



