NLP에서는 Transformer model이 2017년 나타난 이후로 BERT, GPT 등의 모델들이 나타나면서 큰 발전이 있었다.
Computer vision task에서는 여전히 CNN 기반 모델들이 SOTA를 차지하다가, Transformer model에 관한 논문으로 ICLR 2021에 실린 논문으로 ViT가 등장하면서, 기존 SOTA와 견줄만하거나 그 이상의 성능을 보여주는 모델들이 등장하기 시작했다.
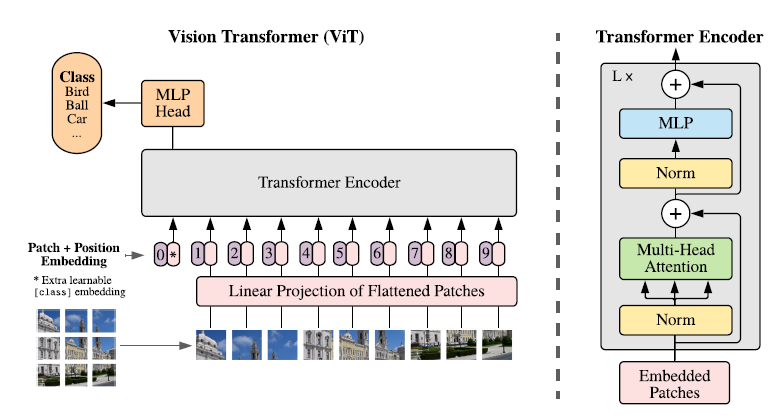
Transformer에 NLP처럼 1D sequence가 아니라, image를 input으로 사용하려면 새로운 접근 방식이 필요하고, 논문에서는 이를 patch라는 개념을 적용해 해결했다.
Transformer 모델은 CNN과 비교했을 때 inductive bias가 부족한데, 이를 해결하기 위해서는 데이터의 양이 충분해야 한다고 설명하고 있다.
<2.> ViT
Model Overview
Overview
Transformer Encoder를 여러 번 stack 한 구조다. Multi-head Attention은 attention mechanism을 병렬로 처리할 수 있도록 한 module로 Transformer 논문에서도 살펴보았듯이 연산 속도면에서도 좋고, ensemble 효과도 있다고 볼 수 있다.
구조 자체는 BERT와 굉장히 유사하다. BERT에서도 [Class] Token을 따로 두고 classification에 사용했는데, ViT에서도 이를 따라가고 있다.
Embedding
Transformer: Attention is all you need에서는 token들로 이뤄진 1D sequence를 embedding으로 한 번 전처리를 하고, 그 결과에 sinusoidal positional embedding을 추가한 것을 input으로 사용한다.
ViT에서는 image를 일정 크기의 patch로 자르고, 이 patch들로 sequence를 구성한다.
Positional embedding을 patch embedding에 추가해서, 위치 정보를 담고 있도록 한다.
Inductive Bias
CNN 모델에서는 convolution layer가 locality property를 잘 잡아냄 / 2D neighborhood structure : 이웃 픽셀(feature)들도 같이 고려할 수 있음 / translation equivariance 한 특징이 있기 때문에 모델 전체가 그러한 특징을 갖게 된다.
그러나 ViT에서는 MLP layer만 이런 특성을 갖고 있고, transformer에 있는 self-attention layer의 경우 global한 특징이 있다. 즉, 이미지 전체에 대한 정보를 보게 되어서 patch들간 spatial relation에 대한 학습이 필요하다.
따라서 ViT는 inductive bias가 없다고 할 수 있다. 그에 따라 더 많은 데이터를 통해 학습시켜야 일반화 성능을 갖출 수 있다.
Hybrid Architecture
raw image patch를 사용하는 것보다, CNN model에서 얻은 feature map으로 sequence를 사용할 수 있다.
<3.> Fine Tuning
Large Dataset에 ViT를 pre-train 하고 그 이후 downstream task에 fine-tuning 한다. pre-train에서 사용했던 prediction head를 없애고 DxK 차원의 feedforward network를 만든다. (K는 downstream task class 수)
이 방법은 pre-train시 사용했던 이미지보다 fine-tuning에서 더 큰 이미지를 사용할 때 유용하다.
ViT는 임의의 sequence 길이도 다룰 수 있도록 design되어 있는데, 이 경우 pre-train 과정에서 학습시킨 position embedding이 여전히 의미를 가질 수 있도록 2D interpolation을 사용한다.
<4.> 그 외
Experiment
Transformer encoder를 stack한 수 : 12 / 24 / 36에 따라 ViT-Base / Large / Huge로 구분한다.
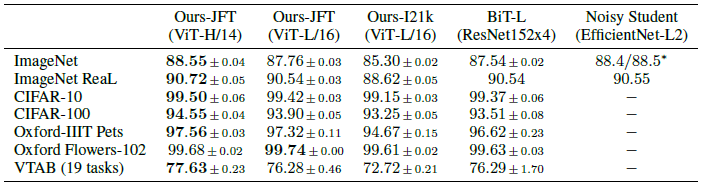
JFT dataset (300M dataset...)을 사용해서 얻은 결과와 CNN기반 SOTA model을 비교했다.
거의 비슷하지만 조금씩 나은 성능을 보여줬다.
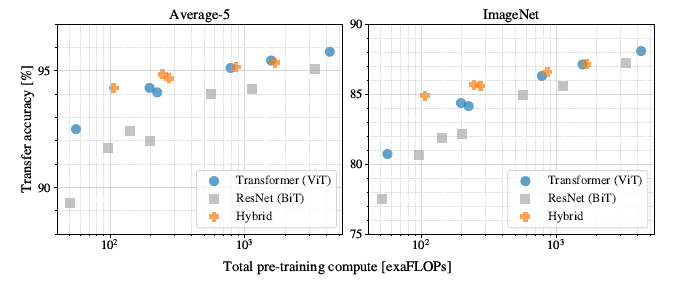
score만 가지고 ViT가 좋다라고 하기에는 JFT dataset을 Google 같은 대기업이 아닌 이상 준비하기도, 사용하기에도 힘들다는 단점이 있다고 봐야겠다. 이 정도 큰 dataset이 아니면 inductive bias 문제로 성능이 떨어질테니까...
그럼에도 연산량 면에서는 CNN 기반보다는 좋다고 봐야겠다. Multi-head의 이점이다.