
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- 알고리즘
- NLP
- level2
- 딥러닝
- 큐
- re-identification
- 3D
- cv2
- Threshold
- Deeplearning
- Python
- Computer Vision
- transformer
- Object Detection
- deep learning
- Object Tracking
- reconstruction
- flame
- 논문 구현
- OpenCV
- 자료구조
- Knowledge Distillation
- 스택
- 프로그래머스
- 파이썬
- point cloud
- 임계처리
- center loss
- attention
- numpy
- Today
- Total
공돌이 공룡의 서재
[논문 리뷰] Accurate 3D Face Reconstruction with Weakly-Supervised Learning : From Single Image to Image Set 본문
[논문 리뷰] Accurate 3D Face Reconstruction with Weakly-Supervised Learning : From Single Image to Image Set
구름위의공룡 2022. 4. 17. 00:58Introduction
사용할 수 있는 3D Face data 가 많지 않다는 것이 문제다. 그래서 이전 연구들은 surrogate shape label 과 같은 고전적인 방법들로 맞춰진 3D shape 이나 합성 데이터를 사용하는 방식을 택했다. 이 방식의 문제는 Domain gap 이 남아있다는 점이랑 label 이 완벽하지 않다는 점이다.
이런 이슈를 해결하기 위해서 라벨 없이 unsupervised 또는 weakly supervised 방식을 사용하는 연구들이 많이 나왔다. 이 연구들의 핵심은 미분 가능한 이미지를 형성하는 것인데, 얼굴 이미지를 네트워크의 예측 결과를 이용해서 렌더링하기 때문에 가능하다. 또한 입력 이미지와 렌더링된 이미지의 차이를 supervision (weakly 인듯) 으로 사용한다.
이 논문에서는 위 연구들의 흐름에 따라, weakly supervised 로 3D face를 생성하는 것을 목표로 한다. Single image 3D Face Reconstruction 과 Multi image 3D Face Reconstruction (한 사람에 대해서 여러 얼굴 사진들이 주어짐)을 하는 핵심 내용들을 간단하게 정리하면 아래와 같다. (Main Contribution)
- Hybrid level loss (=Image level loss + Perception level loss) 로 학습을 시켜서 성능을 올렸다.
- Multi-image face reconstruction aggregation 을 통한 새로운 학습 방법을 제안한다.
Preliminaries : Models and Outputs
3D Face Model
3DMM 모델을 사용하는데 이 모델에서는 face shape (S) 과 texture (T) 를 다음과 같이 나타낸다.
$$
S = S(\alpha, \beta) = \bar S + B_{id}\alpha + B_{exp}\beta
$$
$$
T = T(\delta) = \bar T + B_t\delta
$$
$B_{id}, B_{exp}, B_{t}$ 는 각각 identity, expression, texture 에 대한 scaled 된 PCA base vector 다. $\alpha, \beta, \delta$ 는 각 vector 의 coefficient로, 각각 80, 64, 80 차원 벡터다.
Illumination Model
Lambertian surface 를 가정한다.
램버시안 반사율 (Wiki)
(Lambertian reflectance)을 갖는 표면은, 관찰자가 바라보는 각도와 관계없이 같은 겉보기 밝기를 갖는다.
scene illlumination 은 Spherical Harmonics 로 근사한다. 이 때 쓰이는 SH coefficient 는 총 9개다.
Detail
The radiosity of a vertex si with surface normal ni and skin texture ti can then be computed as C(ni , ti |γ) = ti · PB b=1 γb Φb (ni) where Φb : R3 → R are SH basis functions and γb are the corresponding SH co-efficients.
Camera Model
3D-2D projection geometry 를 위해, perspective camera model 을 사용한다. 3D face pose $p$ 는 Rotation 과 Translation 에 대한 Matrix 로 나타내진다. 이 matrix 의 DOF 는 6으로, p는 총 6개의 미지수로 나타낼 수 있다.
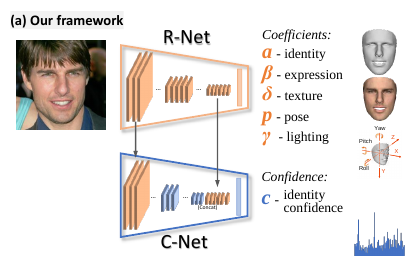
요약하면, 예측해야 하는 파라미터는 총 239개다. ( $\alpha=80, \beta=64, \delta=80,\gamma=9, p=6$ ) ResNet50 네트워크의 마지막 FC layer 를 수정해서 이 값들을 regress 하도록 하였다. 여기서 수정한 ResNet 을 R-Net 이라고 한다.
Hybrid-level Weak-Supervision for Single-Image Reconstruction
Notation : 이미지 I 가 주어졌을 때 R-Net 에서 예측한 파라미터를 이용해서 reconstruct 한 3D Face 의 이미지를 I’ 라고 하자.
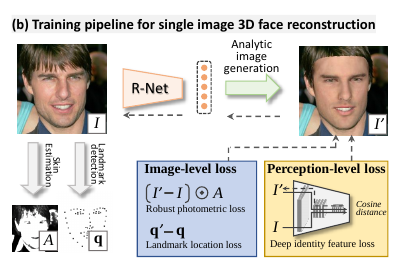
Image-Level Loss
Robust Photometric Loss
raw image 와 reconstructed face image 두 개의 픽셀 차이를 고려하는 방법이다. 얼굴 영역의 픽셀들만 고려한다. 식은 다음과 같다. A는 아래 Skin attention 에서 얻어지는 skin color 다.

Skin Attention:
각 픽셀에 대해서 skin-color probability P 를 계산한다. 이를 위해 skin image dataset 에서 Gaussian Mixture Model 로 naive Bayes classifier 를 학습한다. 각 픽셀에 대해서, P 가 0.5 보다 크면 1, 아니면 P 값을 그대로 갖도록 한다. 이렇게 하면 face segmentation method 필요 없이도 잘 되는 것을 확인했다.
중요한 점은 이 Loss 를 통해 occlusion에 robust 해져서, large pose를 다룰 수 있게 되었다는 점이다.
Landmark Loss
2D 이미지 상의 Landmark 또한 추가로 이용해서 weakly-supervision 으로 네트워크를 학습시킬 수 있다. 학습할 때 만드는 3D Face 에 대해 3D Face alignment method 를 사용해서 3D landmark 를 찾은 다음, pose 를 알고 있으니 2D 로 project한다. 그 다음, 원래 이미지의 landmark (데이터셋으로 주어짐) 픽셀과 project 된 landmark 픽셀 값의 차이를 loss 로 둔다. 식은 다음과 같다.
$$
L_{lan}(x) = \frac{1}{N}\sum_{n=1}^{N} w_N \parallel q_n - q'_n(x)\parallel^2
$$
w 는 각 landmark 에 대한 weight 인데, inner mouth 와 nose point 에 20을 두고 나머지는 1로 두었다.
Perception-Level Loss
Image level loss 만 사용해서 학습하면, 더 부드러운 텍스처를 만들 수 있고 photometric loss 자체도 조금 더 낮지만, 시각적으로 봤을 때 정확하지 않다. 이 점을 해결하기 위해, perception-level loss 를 이용한다.
$$
L_{per}(x) = 1 - \frac{<f(I), f(I'(x)>}{\parallel f(I) \parallel \cdot \parallel f(I'(x)) \parallel}
$$
여기서도 weakly-supervised 방법을 사용하는데, 원본 이미지의 face feature 와 projected 3D face 의 feature 를 뽑아낸 다음에, cosine distance 를 계산한다. Face Feature 를 뽑아내는 것은 FaceNet (Face Recognition model)로 한다.
이 loss 를 사용하게 되면 더 좋은 결과를 얻을 수 있었다.
Regularization
coefficient regularization term 과 texture map variance penalty term 을 둔다. 식은 각각 다음과 같다.
$L_{coef} = w_{\alpha} \parallel \alpha \parallel^2 + w_{\beta} \parallel \beta \parallel^2 + w_{\gamma} \parallel \delta \parallel^2$ , $L_{tex}(x)= \sum_{c\in(r,g,b)}var(T_{c,R(x)})$
Weakly-supervised Neural Aggregation for Multi-Image Reconstruction

한 사람당 여러 얼굴 사진들을 잘 이용하면, pose, illumination 등에 robust 한 face 를 만들 수 있을 것이다. 이를 위해, 저자들은 우선 C-Net 이라는 네트워크를 통해서 Single Image 3D reconstruction 을 할 때, shape coefficient 80개에 대한 confidence 를 예측하도록 한다. 다른 coeffiecient 들은 이미지마다 편차가 크므로 고려하지 않는다. C-Net 의 confidence 를 이용해서, multi image 3D face reconstruction 은 아래와 같이 vector 들을 aggregation 하여 이뤄진다.
$$
a_{aggr} =(\sum_{j}c^j \odot \alpha^j) \oslash (\sum_j c^j)
$$
$\odot$, $\oslash$ 은 각각 Hadamard product 및 divison 이다.
Labe-Free Training
위에서 알아본 hybrid-level loss 를 사용해서, 각 이미지들에 대한 loss 를 모두 합쳐서 한 사람의 이미지 셋에 대한 loss를 다음과 같이 정의한다.

이때, L 식에서 쓰이는 $\alpha_{aggr}$ 을 통해서 역전파가 되므로 C-Net weight를 학습시킬 수 있다.
Confidence-Net Structure
줄여서 C-Net 은 light-weight 로 디자인되었다. R-Net 의 shallow feature map (첫 번째 Residual block 의 feature map) 과 deep feature map (마지막 global pooling layer) 을 재사용한다. 결과적으로는 R-Net 크기의 1/8 사이즈인 모델이다.
Experiment

Loss 식들에 대한 ablation study 및 다른 연구들과 성능을 비교한 것이다. hybrid-level loss function 을 사용했더니 성능이 가장 좋은 것도 볼 수 있다. 아래 table 에서는 average shape error 를 ICP 를 이용해서 계산한 결과로 나타낸 것 같다.

Multi image reconstruction 의 경우에도, aggregation 을 했을 때 error 가 많이 줄어듦을 확인할 수 있다.
'딥러닝 > 3D' 카테고리의 다른 글
| [논문 리뷰] FLAME : Learning a model of facial shape and expression from 4D scans (0) | 2022.04.17 |
|---|---|
| [논문 리뷰] PointNet : Deep learning on Point Sets (1) | 2021.08.30 |
| [논문 리뷰] SMPL-X : Expressive Body Capture (0) | 2021.08.28 |


