
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | 6 | 7 |
| 8 | 9 | 10 | 11 | 12 | 13 | 14 |
| 15 | 16 | 17 | 18 | 19 | 20 | 21 |
| 22 | 23 | 24 | 25 | 26 | 27 | 28 |
| 29 | 30 |
- flame
- Object Tracking
- NLP
- reconstruction
- re-identification
- Object Detection
- numpy
- attention
- cv2
- Computer Vision
- Python
- 알고리즘
- 큐
- 프로그래머스
- Knowledge Distillation
- 임계처리
- 파이썬
- 딥러닝
- 자료구조
- transformer
- OpenCV
- Threshold
- Deeplearning
- point cloud
- level2
- 논문 구현
- 3D
- center loss
- 스택
- deep learning
- Today
- Total
공돌이 공룡의 서재
[논문 리뷰] PointNet : Deep learning on Point Sets 본문
PointNet: Deep Learning on Point Sets for 3D Classification and Segmentation
https://arxiv.org/abs/1612.00593
글을 쓰는 시점에서 인용수가 5천이 넘었다. input으로 point cloud를 직접적으로 다룬 딥러닝 모델이다. 딥러닝 모델에서 point cloud를 다루기 위해서 무엇이 필요한지를 잘 설명하고 있다.

<1.> Introduction
point cloud는 정해진 format이 없기 때문에, 전에 있던 대부분의 연구가 이를 3D voxel grid로 바꾸거나 image들의 집합으로 바꾸고 난 후에 딥러닝 모델에 넣었다. 그러나 이렇게 처리하는 것은 데이터의 natural invariance를 가릴 수 있는 quantization artifact가 있을 수 있다. (continous space에서 discrete space로 옮겨서 그런 것 같다)
이러한 이유에서 이 논문에서는 point cloud를 input으로 이용한 모델을 제안한다. point cloud는 mesh처럼 어떠한 조합으로 이뤄진 것이 아니기에 더 다루기 쉬운 모델일 수 있다. (mesh의 경우 vertex 3개로 이루어진 triangle mesh를 말할 수 도, 또는 렌더링 결과로 나온 mesh를 말하는 것일 수 있겠으나, 어쨌든 이웃하는 점들의 조합을 고려해야 한다.) point cloud는 단순한 점들의 조합이므로 permutation invariant 해야 하며, rigid motion에도 invariant 해야 한다. (점들이 어떤 순서의 변수로 오든 달라지는 것이 없으며, 점들 전체를 회전하거나 이동시킨다고 해서 3D 형체가 달라지는 것이 아니기 때문이다.)
이 섹션에서 PointNet 모델에 대해서는 다음과 같이 소개하고 있다.
- input을 point cloud, output은 input 점들에 대한 class label이나 segmentation label, 등으로 처리한다는 점에서 unified model이다. (다루는 data의 타입이 바뀌진 않는다.)
- 기본적인 구조는 간단한데, 각 layer의 역할은 점들을 모두 동일하게(identical) 처리하거나 독립적(independent)으로 처리하거나 둘 중 하나를 맡는다.
- max pooling을 사용한다. interesting 또는 informative point를 고르는 기준을 학습하고 그 기준에 대한 근거를 encode 하게 된다.
- FC layer을 사용한다. max pooling 결과로 나온 값들을 모아서 global descriptor로 만든다. 이 descriptor는 entire shape이나 per point label에 쓰인다.
- data-dependent STN(spatial transformer network)를 PointNet에 넣기 전에 추가해서 성능을 좀 더 높였다.
- 모델 구조를 수식으로 표현했을 떄, 연속인 set function을 approximate 할 수 있는 모델이다. 즉, point cloud를 다루는 것에 적합하다고 설명한다.
- 네트워크는 input point cloud를 sparse set of key points(=시각화했을 때 skeleton에 해당하는 점들)로 summarize 하는 것을 학습한다. (max pooling 때문인 것 같다.) 뒤에서 나올 upper bound shape point나 criticial point들이 그러하다.
- PointNet이 outlier나 data missing 같은 input point의 perturbation(작은 변화)에도 강하다.
key contribution으로는 다음과 같이 설명한다.
- 3D에서 unordered point set을 다루기에 적합한 딥러닝 모델 디자인
- shape classification, part segmentation, scene semantic parsing task, 등에 사용할 수 있음.
- model의 stability와 efficiency에 대한 실험적 / 이론적 분석 제공 - 논문 Analysis 섹션에서 확인해볼 수 있었다.
- 네트워크에서 학습하고 고른 3D feature에 대한 illustrate - 논문 Experiment 섹션에서 확인해볼 수 있었다.
<2.> Related work : 기본 개념 정리
좀 익숙한 분야의 논문이면 related work가 다 다루는 게 비슷비슷해서 작성을 잘 안 하는데 3D 딥러닝 모델을 제대로 공부하려면 알아야 할 것 같아서 기록 목적으로 적어두려 한다.
- Point cloud features:
- 기존에 있었던 방법들: 통계적인 특성을 encode해서, certain transfomation에 invariant 하도록 디자인됨.
ex) intrinsic vs extrinsic 또는 local features vs global features
- 기존에 있었던 방법들: 통계적인 특성을 encode해서, certain transfomation에 invariant 하도록 디자인됨.
- Deep learning on 3D data:
- Volumetric CNN: 3D convolutional neural network
- volumetric representation은 data sparsity와 3d conv의 연산량 때문에 제약이 있음.
- 그 외 모델로는 FPNN, Vote3D : large point cloud에는 불가능
- Multi-view CNN : 3D point를 2D로 렌더링 하고, 그 이미지에 conv net을 적용
- Spectral CNN , Feature based DNN, 등
- Deep learning on Unordered Sets
- point cloud는 vector들의 unordered set이라고 볼 수 있음
- 지금까지 대부분의 딥러닝 모델이 sequence나, image, volume 같은 regular input에 대해 초점이 맞춰져 있기 때문에, 이에 대한 연구가 별로 없음 → 이 모델의 contribution이 의미 있는 이유!
<3.> Problem Statement (문제 설정)
각 point는 x,y,zx, y, z coordinate 좌표 정보뿐 아니라 feature channel (color, normal) 등을 갖고 있다. 이 모델에서는 간단히 x, y, z만 사용하기로 한다.
classification 문제에서는 input point cloud는 scene point cloud의 shape에서 샘플링해서 얻거나 사전에 segementation을 거친 결과를 사용한다. output은 k개의 class에 대해 k score들을 가진다. 그중에서 max가 되는 class로 분류하면 되겠다.
semantic segmentation 문제에서는 input으로 part region segmentation에서 얻은 single object 또는 3D scene에서 sub-volume가 될 수 있다. output은 nxm (n은 point 수, m은 semantic category 수) score를 사용한다.
<4.> Properties of Point Sets
딥러닝 모델에서 point cloud를 다루기 위해서는 다음과 같은 조건이 필요하다고 한다. 논문에서 중요한 부분 중 하나다.
- data가 들어가는 순서가 전혀 상관이 없다. N개의 3D point가 있다고 하면, 네트워크는 N! permutation에 대해 invariant 해야 한다. (이유는 위 introduction에서 언급했다.)
- 점들 간에는 interaction이 존재한다. 점들은 특정 거리를 두고 구분되어 있는데, 이웃하는 점들은 lcoal geometry 면에서 의미가 있다. 그래서 모델은 이런 local 한 특징도 잘 잡아낼 수 있어야 한다.
- transformation에 invariant해야함. 점들을 변환시킨다고 해서 class 분류 값이나 segmentation값들이 변하면 안 됨.
<5.> PointNet Architecture
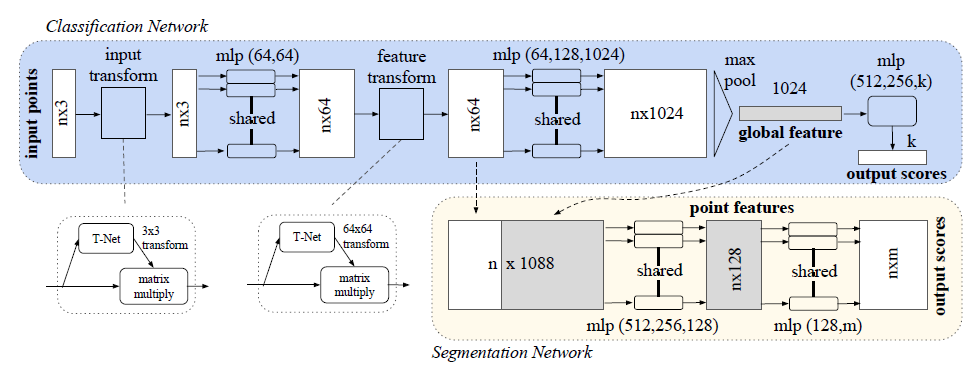
모델 구조에서 핵심으로 아래 3가지를 소개하고 있다. (Key module)
- max pooling - aggregate info. from all the points
- local & global information combination structure
- two joint alignment network
key module들에 대해 자세히 알아보자
우선 model이 input permutaton에 invariant 하려면 어떻게 해야 하는가로 시작한다. 아래 3가지 방법을 소개한다.
- input을 canonical 하게 정렬
- input을 seq처럼 다룸. 단, 모든 permutation에 대해 augment
- symmetric fucntion을 사용함. ex) +와 *는 symmetric binary function
1번은 고차원 공간에서 point perturbation (쉽게 생각해서, 데이터에 자그마한 변동을 주는 것)에 stable 한 order가 존재하지 않으므로 고려할 수 없다.
2번은 모든 permutation을 고려한다면 RNN 같은 모델이 invarint 할 수 있으나, N개의 point에 대해 N! 의 순서들이 생기고, 이런 large scale에도 적용 가능한지 보장할 수 없다. 실제로 PointNet 모델보다 성능이 좋지 않았다고 한다.
그래서 결국 3번 방법을 선택했는데, 핵심은 mlp와 max pooling을 사용한다는 것. 그리고 symmetric 한 function을 사용함으로써, general function(모델 전체를 함수 수식으로 표현했을 때)을 symmetric function으로 근사할 수 있고 결국 permutation - invariant 하게 된다.
mlp의 경우 layer size에 맞춰서 node가 있다고 했을 때, 이 node들이 weight를 sharing 한다. 즉, input으로 들어오는 값들에 대해 갖는 weight들이 같다. 그러면 point들 간 정보는 어디서 얻냐면 바로 max pooling에서 얻는다. 전체 point data에서 max라는 특수한 정보를 가져오기 때문이다.
<6.> Local and Global Information aggregation
classification과 달리 point segmentation은 local & global knowledge가 둘 다 필요하다. 그래서 global feature vector를 계산하고 나서, 각 point에 이 feature를 붙인다. (위의 그림 참고) 붙이고 난 결과를 input으로 사용해서 segmentation branch에 통과시키면 새로운 per point feature를 얻는다. 이렇게 하면 global + local 둘 다 얻는다고 볼 수 있다. modification을 조금 하면 local geometry와 global semantic에 대한 qunatities를 예측할 수 있다고 한다. ex) per-point normal, 등.
<7.> Joint Alignment Network
Transformation에 invariant 하도록 하려면 어떻게 해야 할까에 대한 설루션이다.
이 논문에서는 T-net이라는 mini-network를 사용한다. affine transformation matrix에 해당하는 network로 이 network를 통과했는데도 semantic labeling이 그대로 나온다면, invariant 하다고 볼 수 있다고 한다.
(이 문단에서는 T-net에 대해서 설명한다.) 논문에서는 이 개념을 feature space의 alignment로 확장할 수 있다고 보았다. 다른 input point cloud에서 나온 feature와 align 하기 위한 transform을 예측하는 또 다른 네트워크를 사용한다. (two joint alignment network인 이유) 다만, feature space에서 transformation matrix는 spatial transformation matrix보다 higher dimension이라서, 최적화의 어려움이 생긴다.

따라서 regularization loss term을 추가했는데 feature transformation matrix가 orthogonal matrix에 가깝게 식을 설정했다. transformation이 orthogonal 해지면, input에 대한 정보를 잃지 않기 때문이다. 추가했더니 more stable & better performance 하다고 한다.
<8.> Experiment - application
3D object classification:
12311 CAD model들을 사용하고 75% 정도 train, 25% test set으로 나눴다.
input point cloud는 mesh faces에서 1024개 point들을 sampling 함. 그러고 unit sphere로 normalize 했다.
data augmentation으로는 up-axis 축을 따라 랜덤 하게 회전시키거나, 값에 gaussian noise를 넣는 것을 사용했다.
3D object part segmentation:
part segmentation 문제를 per-point classification problem으로 고려한다.
metric으로는 shape의 mIOU 사용했다. 겹치는 point 수들을 IOU에 포함시켜서 측정한다.
3D part segmentation
각 point는 X, Y, Z 좌표 정보 외에 R, G, B, + normalized location 정보를 사용한다. 즉, point 하나당 9-dim vector다. 여기에 추가로 hand-craft point features로서 local features, local curvature, normal를 추가해서 12-dim vector를 사용했다.
<9.> Experiment - Architecture Design Analysis
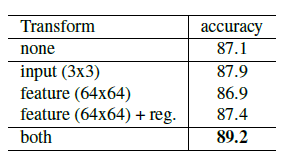
- 위에서 설명한 unordered data set에 대한 strategy들을 다 시험해본 섹션이다.
- max pooling vs average pooling vs attention 중에서 max pooling이 가장 성능이 좋았다.
- input transformation, 즉 STN을 적용했더니 성능 조금 더 좋아졌다. 또한 regularization term도 효과가 있었다.
- MVCNN이랑 3D CNN은 성능은 좋지만 convolution layer 때문에 연산량이 많음. 그러나 pointNet은 O(N)이라서 효율적



