
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | ||||
| 4 | 5 | 6 | 7 | 8 | 9 | 10 |
| 11 | 12 | 13 | 14 | 15 | 16 | 17 |
| 18 | 19 | 20 | 21 | 22 | 23 | 24 |
| 25 | 26 | 27 | 28 | 29 | 30 | 31 |
- Python
- reconstruction
- attention
- center loss
- Object Detection
- flame
- 논문 구현
- 프로그래머스
- 3D
- Knowledge Distillation
- point cloud
- 큐
- Computer Vision
- 자료구조
- 파이썬
- level2
- numpy
- Object Tracking
- transformer
- Threshold
- OpenCV
- cv2
- 딥러닝
- NLP
- 스택
- 알고리즘
- Deeplearning
- 임계처리
- re-identification
- deep learning
- Today
- Total
공돌이 공룡의 서재
[논문 리뷰] Distilling the Knowledge in a Neural Network 본문
1. Introduction
기존에 있는 방법들의 issue들을 언급한다.
- cumbersome model
- 좋은 성능을 내기 위해서는 model ensemble 방법을 사용할 수 있으나, 연산량이 많고 시간이 오래 걸린다.
- side effect of normal training
- 일반적인 학습은 올바른 답에 대한 평균 확률을 최대화하는 것이 목표다.
- 이런 방식은 모든 오답에도 확률을 할당한다. 예를 들어서, category로 트럭과 BMW와 당근이 있다고 하고 실제 이미지는 BMW라 하자. 모델이 트럭으로 판단할 확률이 작아도 존재하고, 이 확률은 당근으로 판단할 확률보다는 훨씬 큰 값이다.
- 이는 모델이 training data만으로 어떻게 일반화를 하는지를 말해준다.
이 Intro에서 말하고자 하는 Knowledge Distillation의 핵심은 cumbersome model model이 하는 방식으로 small model이 학습할 수 있다는 것이고, 결과적으로 small model이 normal training 방법으로 하는 것보다 더 좋은 성능을 가질 것이라는 것이다.
방법으로는 다음과 같이 소개하고 있다.
- Cumbersome model의 결과로 나오는 class probability를 small model이 학습할 때 쓰는 soft target이라 간주한다.
그렇다면 soft target은 어떤 효과가 있는 것인가?
- soft target은 high entropy라서 일반적인 학습에 사용하는 hard target보다 information이 많다.
- training gradient 간에 gradient의 variance가 작아서, small model이 적은 data로도 효율적으로 학습이 가능해진다.
Transfer set (Distillation에 사용할 Data set을 말함)으로는 unlabeled data를 사용할 수도 있고 original training dataset을 사용할 수 있다. 논문 저자들은 original training set을 사용할 때 loss function에 soft target에 대한 term을 추가한다면 잘 동작함을 확인했다고 한다.
2. Distillation
Intro 의 내용을 바탕으로, Distillation은 잘 학습된 large model 이 주는 결과를 바탕으로 small model 역시 좋은 성능을 내도록 하는 과정이라 설명할 수 있을 것이다. 그럼 이제 구체적으로 들어가보자.

일반적인 Softmax 식을 떠올려보자. T=1이라면 Softmax와 똑같아 진다. Softmax는 간단히 복습하자면, 각 class에 해당하는 logit 값을 다른 클래스의 logit 값과 비교하여 확률의 형태로 바꾸는 것이다.
위 식에서는 T가 높아질수록 probability distribution이 soft한 형태를 갖게 된다고 한다. small model로 knowledge를 전이할 때는 높은 T를 쓰다가, 학습이 끝나면 small model은 T=1을 사용한다.
두 가지 loss function을 weighted average로 동시에 사용한다. 식은 다음과 같다.
- cumbersome model 이 주는 soft target과 distilled model이 내놓는 softmax 사이의 cross entropy. → 이 때 두 model 에서 계산 시 사용하는 temperature는 같아야 함.
- correct label에 대한 cross entropy
→ Temperature는 1.
여기에 추가적으로, 논문 저자들은 2번째 term에 더 낮은 wieght를 주는 것이 best result라고 한다. 또한 soft target의 경우 미분시 생기는 scale 문제때문에 값에 temperature의 제곱만큼을 중요하다고 한다. → 그래야 temperature 에 상관없이 hard target과 soft target의 상대적인 contribution이 유지된다고 보았다.
이 내용만 이해했어도 이 논문에서 가장 중요한 부분은 이해했다고 봐도 될 것 같다.

조금 더 개념적인 부분에서 부연 설명을 해보겠다. 우리가 동물이 어떻게 생겼는지 아예 모르는 딥러닝 모델이고, 그림들을 보며 특징을 알아내서 학습하고자 한다. 위 사진처럼 단순하게 정답에만 동그라미가 있는 것보다는 다른 선택지들에 대해 고민해본 흔적이나 단서들이 있다면 학습에 도움이 될 것이다. 이를 도식화해서 나타내면 다음과 같다.

2.1 Matching logits is a special case of distillation
Cross entropy 식을 distilled model에서 나오는 logit (z) 으로 미분하면 식은 다음과 같다. (이 때 v는 cumbersome model의 logit이며, 이 model 내놓는 soft target을 p라 하자.)

이때 temperature T가 logit 값보다 더 크다면, 지수가 0에 가까워지고 exp 함수의 특성상 1에 가까워진다. 따라서 다음과 같은 근사가 가능해진다. (N은 클래스의 수다.)
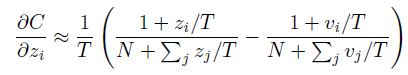
여기서 logit 값이 zero-mean이라고 가정한다면, 위 식은 아래와 같이 단순화가 가능해진다.
logit이 0과 1로 이루어져있을텐데, multi-class 에 대한 one-hot encoding을 생각해보자. 굉장히 sparse한 1D vector이므로, zero-mean이라고 볼 수 있을 것이다.
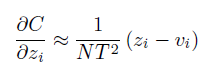
lower temperature에서 distillation은 small ↔ cumbersome 사이의 평균보다 더 negative한 logit을 matching하는데 attention을 덜 주게 된다고 한다.
무슨 말인가 의아했는데 temperature가 값이 작으면 soft target의 distribution function이 soft한 정도가 떨어져서 one-hot encoding에 가까워진다. 따라서 negative logit들간 차이가 작아진다. 반면 temperature가 크다면 soft해져서 soft target의 negative logit에 대한 값이 좀 더 커지므로 distilled model의 negative logit과의 차이가 더 커진다.
논문 저자들은 적절한 temperature를 정하는 것은 empirical 하며, 적정한 값(너무 높지도, 낮지도 않은) 을 설정하는 것이 가장 성능이 좋았다고 한다.
3, 4 Experiment - MNIST , Speech
결과를 요약하면 Distilled model이 충분히 좋은 성능을 보여주고 있다는 것이다. 다른 포인트를 찾아보면 다음과 같다.
- Distilled net이 각 layer당 300개가 넘는 unit들이 있다면, 8을 넘는 temperature는 다 비슷한 결과를 보여주었다. 반면 각 layer당 30개 정도로 unit의 수가 확 줄어든다면 2.5~4 정도의 temperature로 설정하는 것이 좋은 성능을 보여주었다.
→ 실제로 distillation을 사용할 때 참고할만한 사항이다.
5. Training ensembles of specialists on very big datasets
model ensemble의 단점을 한 번 더 언급하고 있다. 모델이 매우 크고 사용하는 데이터셋도 크다면, 연산량이 매우 많아 시간이 굉장히 오래 걸린다.
논문 저자들은 이 section에서 어떻게 각각 specialist model (클래스들의 부분집합에 주목하는)들이 전체 연산량을 줄일 수 있는지를 보여주고, 이런 모델들이 가지는 main problem (fine-grained 차이점에 주목하는 것)을 soft target을 통해 어떻게 해결했는지를 보이고자 한다.
5.1 JFT dataset
구글의 JFT dataset은 15000 클래스에 1억장의 라벨링된 이미지가 있는 데이터셋이다. (ViT에서 접해봤을 것이다.) JFT로 학습을 시킨 방법으로 2가지 병렬 프로그래밍을 언급하고 있다.
- 여러개 코어에 replica를 놓고, 각각 다른 mini-batch를 계산하여 average gradient와 parameter를 서버에 보낸다.
- 각 replica는 여러 코어에 퍼져있는 형태다. (한 코어에 한 replica가 통째로 들어가는 1번과 달리, 일부분이 조금씩 들어가 있는 형태)
앙상블보다는 이 2가지 방법이 더 빠른 방법이라 한다.
이게 KD와 무슨 상관이 있을까... 싶네
5.2 Specialist Models
class 수가 굉장히 많을 때, cumbersome model을 이런 class들 전체에 학습시킨 generalist model이라 하자. class 의 헷갈릴만한 일부분만 사용해서 학습시킨 specialist 를 생각해볼 수 있다. (ex. 여러 종류의 버섯들을 분류하는...?)
overifitting을 줄이고 low-level feature 학습을 공유하기 위해, 각 specialist는 generalist model의 weight로 초기화한다. 이런 weight들은 specialist 모델이 특별한 subset으로 오는 예시로 절반, training set의 남은 부분에서 랜덤하게 뽑아서 절반으로 데이터를 구성해서 학습할 때 조금씩 수정된다. (specialist model의 학습 방법을 언급하는 것 같다.)
5.3 Assigning classes to specialist
specialist model은 generalist model이 많이 헷갈리는 카테고리에 집중하도록 하는 것이 요점이다. 그럼 어떻게 이런 카테고리(class)를 뽑아서 할당할 것인가?
논문에서는 generalist model의 prediction 결과들로 만든 covariance matrix에 clustering 알고리즘을 적용하는 방법을 제안한다. 자주 같이 예측되는 클래스들(=모델이 헷갈리는 클래스들)을 묶어서 할당하는 것이다.
5.4 Performing inference with ensembles of specialists
JFT 데이터셋으로 학습할 때, baseline model은 full network 로 잡았다. 비교 대상은 specialist model 61개로 각각 300개의 클래스 subset으로 학습시킨 방법이다. (JFT는 총 15000개 정도 클래스니까) 실험 결과, 학습 속도도 후자가 훨씬 빨랐고 성능도 후자가 조금 더 좋은 것으로 나타났다.
6. Soft Targets as Regularizers
사실 섹션 3,4,5 보다는 이쪽 내용이 더 중요한 것 같다. soft target이 어떤 효과가 있는지 좀 더 자세하게 나온다.
논문 저자들의 주장은 soft target은 hard target에서는 encoding될 수 없는 정보들을 갖고 있다는 것이다. (Introduction에서도 언급되었다.)
이 섹션에서는 이에 대한 실험 결과로 주장에 대한 근거를 제시하고 있다. 전체 데이터의 3% (3%라 해도 JFT가 워낙 커서 20M이나 되긴 한다.) 를 사용해서 hard target으로 학습했을 때는 overfitting이 심했지만, soft target으로 했을 때는 정확도가 full training set을 사용한 것처럼 유사하게 나왔다.

그러면서 6.1 에서는 specialist를 knowledge distillation을 통해 학습할 때는 더 작고 효율적인 크기의 training set이 있을 것이라는 가능성을 제시하고 있다.
soft target에 대한 효과에 대해 오로지 test accuracy로 근거를 들고 있다. 따라서 구체적인 수식에 대한 설명이 부족한데, 몇 년 후에야 label smoothing의 효과에 대한 논문이 나온 걸로 알고 있다. (NIPS)
7. Relations to Mixtures of Experts
이 섹션에서는 specialist model들을 여러 개 학습하는 것에 대한 내용이다. 사실 위 섹션들이랑 겹치는 내용들이 많다.
결론은 specialist model 을 여러 개 학습할 때도 모델 하나 당 전체 데이터의 일부분을 주고 학습하는 것이 좋다는 것이다.
이에 반대되는 개념으로 gating network 라는 것을 도입해서 어떤 데이터를 어떤 모델에게 주어줄 지를 결정하게 하는 방법을 생각해볼 수 있는데, 사실상 여러 이유로 병렬화하기 힘들다. specialist가 각각 data subset 을 갖고 학습하는 것이 병렬화해서 학습하기 훨씬 편한 방법이다.
마무리
의의
- Knowledge Distillation에 대해 처음으로 소개하는 논문이다. Teacher model과 Student model이라는 개념을 제시했다.
- 엄밀히 말하면, 본문에서는 Cubersome(또는 generalist)이 Teacher model, Specialist(또는 expert) 가 Student model에 대응하는 개념이다.
- 데이터 전체에 대해 학습하는 것이 아니라 일부분만 주고 특정 카테고리에 특화되어 있는 모델을 만들고자 하기 위함이기 때문이다.
- Soft target이라는 개념이 제시되었다. Hard target이 일반적으로 알고 있는 라벨인데 (one-hot encoding) Hard target에는 없는 정보를 Soft target이 담고 있다고 설명하고 있다.
- MNIST 와 speech recognition에 실험한 결과를 토대로, 딥러닝 전반에 사용 가능한 방법임을 제시하고 있다.
아쉬움
- Soft target에 대한 설명이 아쉽다. 실험적인 근거만 이용하여 ~일 것이다 라는 가정을 뒷받침하고 있기 때문이다.
- 중복되는 내용들이 많아서 논문이 좀 뒤로 갈수록 지루해졌던 것 같다.
- 실험 세팅에 대한 자세한 설명이 부족해서, reproductivity가 부족한 것 같다. 실제로 누구나 같은 효과를 볼 수 있을지는 잘 모르겠다.
'딥러닝 > Model' 카테고리의 다른 글
| [논문 리뷰] Learning Efficient Object Detection Models with Knowledge Distillation (0) | 2022.03.29 |
|---|---|
| [논문 리뷰] CBAM : Convolutional Block Attention Module (0) | 2021.08.25 |

