
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | 5 | ||
| 6 | 7 | 8 | 9 | 10 | 11 | 12 |
| 13 | 14 | 15 | 16 | 17 | 18 | 19 |
| 20 | 21 | 22 | 23 | 24 | 25 | 26 |
| 27 | 28 | 29 | 30 |
- Computer Vision
- Object Tracking
- cv2
- Knowledge Distillation
- 딥러닝
- 파이썬
- deep learning
- center loss
- re-identification
- attention
- 논문 구현
- Threshold
- 임계처리
- level2
- OpenCV
- Deeplearning
- Object Detection
- flame
- Python
- point cloud
- NLP
- 큐
- 알고리즘
- 자료구조
- numpy
- 프로그래머스
- transformer
- 스택
- reconstruction
- 3D
- Today
- Total
공돌이 공룡의 서재
[논문 리뷰] Transformer : Attention is All you need / NLP (자연어처리) 모델 트랜스포머 본문
[논문 리뷰] Transformer : Attention is All you need / NLP (자연어처리) 모델 트랜스포머
구름위의공룡 2021. 2. 9. 19:58<1.> 배경
이전에 자연어 처리에서 사용했던 모델들은 recurrent model을 사용한다. 이 모델은 병렬 처리를 사용할 수 없어서 속도가 느리다는 단점이 있었고, 거리가 먼 단어들에 대해서 학습시키기 어려운 단점이 있었다. 이에 대한 해결책으로 거리에 상관없이 단어들의 의존성을 학습시킬 수 있도록 Attention 이 고안되었다. 그러나 Attention 또한 recurrent model과 같이 쓰이므로 어느 정도 한계를 보였다. 이런 배경 속에서, Recurrent model을 쓰지 않고 Attention만 사용하며, 병렬 처리도 가능한 Transformer가 개발되었다. 글을 쓰는 시점에서 인용수가 17000을 넘는다. 이후 나올 BERT, GPT, XLNet, 등의 뿌리가 되는 논문이라서 매우 중요한 듯.
<2.> 전체 구조

인코더와 디코더를 여러 개 사용한 모델(Stacked-Encoder & Decoder)로 세부적인 구조는 아래 그림과 같다. 인코더는 두 개의 sub layer(Multi-Head Self-Attention과 Feed Forward Neural Network(이하 FFNN))로 이루어져 있다. 디코더는 3개의 sub layer(Masked Multi-Head Attention, Multi-Head Attention, FFNN)으로 구성되어 있다.

논문에선 인코더와 디코더의 개수(=N)를 6으로 설정했고 따라서 전체적인 구조는 그림 2와 같다. top에 있는 인코더의 Output이 각 Decoder의 Multi-Head Attention에 Input으로 들어간다. 모든 sub-layer에는 residual connection이 사용되었다. 따라서 Add & Norm을 거치고 나면 LayerNorm(x+sublayer(x)) 값이 결과로 나오고, 다음 sublayer또는 다음 인코더/디코더의 입력값으로 쓰인다. Embedding 된된 Input Text에 대해 Positional Encoding을 더한 값을 인코더의 Input으로 사용한다. 논문에서는 output dimension을 512로 설정하고 있다. Attention is All you Need라는 논문의 제목처럼, 어떻게 attention으로만 다른 모델들보다 우수한 성능을 보일 수 있었는지를 살펴보자.
<3> Attention

우선 Transformer에서 Attention은 종류가 3가지다. 인코더의 self-attention부터 이해해보자. Query, Key, Value가 input sequence 내에서만 생성되므로, self-라는 이름이 붙여졌다. 자기 자신 안에서 Attention이 이뤄지는 것이다. 디코더에서 Masked가 붙여진 이유는 Attention을 구하는 과정에서 Query가 입력 시퀀스에서 n번째 단어라고 한다면, n번째 이후의 단어는 생각하지 않기 때문이다. 이렇게 함으로써 디코더에서 다음에 나올 단어를 예측하는 능력을 높일 수 있다. 논문에서는 디코더의 자기 회귀 능력을 보존할 수 있게 된다고 설명한다. 마지막으로 Encoder-Decoder Attention에서는 Query는 밑의 디코더에서 받아오고, key와 value는 인코더의 맨 위에서 나온 값에서 가져오기 때문이다. (이 점에서, 전에 그림에서 맨 위 인코더에서 각 디코더로 가는 화살표의 의미는 이 key와 value를 encoder-decoder attention에 전해주는 과정을 나타낸 것으로 이해할 수 있다.)

이렇게 설명하면 이해가 잘 안 될 텐데, Query, Key, Value라는라는 개념을 좀 더 알아보자. (이하 각각 Q, K, V) 데이터베이스에서 나오는 개념인데, Q란 정보를 요청하는 것이고, K는 조건에 맞는 속성들, V는 이들에 대한 값 정도로 생각해볼 수 있다. Key-Value pair의 경우 파이썬의 dictionary를 생각해보면 이해가 더 쉽다.
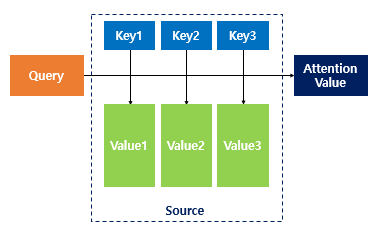


Attention에서 그럼 이 개념들이 어떻게 적용되는지를 이해해보자. attention이 처음 소개된 논문에서는 context vector를 구하기 위해서, attention score에 해당하는 weights(α )와 value(시퀀스 내 단어, hj )를 곱한다. 여기서 attention score는 Q와 K를 a(=alignment model)에 입력으로 넣음으로써 구한 값들에서 softmax 식을 적용해 구한다. si-1 (이전 hidden state)가 Q에 해당하고, hj 가 key에 해당한다. 이 개념이 transformer에서도 비슷하게 적용된다. (계산 방식이 다르나 Q, K, V 개념은 유사함) 예를 들어, self-attention의 경우 입력 시퀀스 내의 특정 단어가 Q에 해당하고, 시퀀스 내 모든 단어들이 K와 V에 해당한다. 즉, Q는 giver, K는 receiver에 해당한다.
지금까지 attention의 종류와 query, key, value에 대해 살펴보았으니 다음은 논문에서 소개하는 Scaled Dot-Product Attention에 대해 알아보자. embedding word에 대해 weight matrix를 곱하면 해당 단어의 Q, K, V를 얻을 수 있다. X가 시퀀스의 길이x임베딩 크기(논문에서는 512로 설정하고 있다)의 matrix라면 (이 때 X의 각 행은 단어의 임베딩 벡터를 의미한다), W는 임베딩 크기x벡터 사이즈 (논문에서는 64로 설정하고 있다. 이유는 차후에 다시 설명) 의 matrix다. 이때, Q와 K를 곱한 값을 단어들간 유사도를 계산한 score이라 생각해볼 수 있고, 벡터 사이즈의 루트 값으로 이 값을 나눈 다음에 softmax에 넣는다. 그 결과 나온 값을 V랑 곱한다.


여기서 scaling하는 이유는 역전파가 좀 더 안정적으로 이뤄지게끔 할 수 있기 때문이다. softmax를 하면 0 ~ 1 사이의 값으로 나오는데 이는 다른 단어와 얼만큼 관련 있는지를 나타내는 attention probability를 의미한다. 이 결과가 다시 V(다른 단어들)과 곱해짐으로써 attention이 반영된 sequence를 구할 수 있게 되는 것이다. WQ, Wk, WV 를 훈련을 통해 update를 시키면서, Q가 giver, K가 receiver로서의 역할을 더 잘 수행할 수 있도록, 또는 단어들에 대한 attention이 더 잘 이뤄지도록 할 수 있다.
공부하면서 든 의문점은 왜 임베딩 결과로 나온 벡터들로 Q, K, V를 만들지 않고 따로 matrix 곱을 통해 만들까? 였다. 그 이유는 latent representation을 더 잘 나타낼 수 있으며, matrix곱을 통해 벡터의 크기를 많이 줄일 수 있어서 연산 양에 있어서 효율적이기 때문이었다.

이제 Multi-Head Attention을 알아보자. 구조는 위 그림과 같이 나타나는데, transformer의 강력한 성능을 보여주는 이유 중 하나다. 우선 속도면에서 살펴볼 때, RNN같은 recurrent model의 경우 병렬 처리가 불가능한데 이처럼 Attention을 여러 개(논문에서는 8개)를 사용하면 병렬 처리가 가능하다. output dimension이 512였는데, 이 값을 8로 나눈 것을 single attention의 dimension으로 설정해준다면 병렬로 사용할 수 있다. 이것이 Q, K, V 벡터 사이즈를 64로 설정한 이유다. 성능면에서는 어떨까? 우선 각 Single Attention의 WQ, Wk, WV 가 초기화도 다르게 되고 update되고 난 결과도 다르게 얻어질 것이다. 따라서 조금씩 attention 정도가 다른 결과를 줄 것이므로, 단순히 생각하면 ensemble 효과로 볼 수 있으며 좀 더 깊게 생각해보면 입력 시퀀스의 context 또는 단어간 의존도(또는 attention)를 여러 시각에서 접근함으로써 더 정확한 결과를 얻을 수 있게 된다고 할 수 있다.
<4> Position-Wise Feed-Forward Network
attention sub layer의 결과로 나온 벡터는 일종의 context가 반영된 sequence라고 볼 수 있는데, 이 벡터가 FFNN에 입력으로 들어간다. FFNN은 입력층(512) – 은닉층(2048, 활성화 함수=ReLU) – 출력층(512)의 구성이다.
<5> Positional Encoding
여기까지 이해했다면, Attention과 FFNN을 통해 단어들간 의존도를 파악하는 것을 잘할 수 있는데 그래도 문장 내에서 단어들의 순서를 고려하지 않을까? 라는 생각이 들 수 있다. 이를 위한 해결책이다. 입력 텍스트가 인코더의 입력으로 들어가기 전에 임베딩 벡터로 바뀌고, 벡터에 positional encoding vector를 더한다. 이 인코딩 벡터는 sin과 cos값으로 구성되어 있다.


위에서 보이는 수식에서, pos는 position, i는 입력 시퀀스의 크기를 뜻한다. 그렇다면 왜 이와 같은 삼각함수를 썼을까? 이에 대해선 몇 가지를 고려해야 한다. 입력 시퀀스의 길이가 변하더라도 (문장의 길이는 다양하다.) 적용이 가능해야 하며, 단어간 절대적 거리를 나타내 순서를 나타낼 수 있어야 하며, 문맥에 따른 상대적 거리를 계산하는 것에도 이점이 있어야 한다. 순서를 적용하는 방법으론 단순히 단어에 1, 2, 3, 4... 의 값을 더하거나, 또는 1/(문장의 길이), 2/(문장의 길이), ... 를 더하는 방법을 생각해볼 수 있다. 그러나 이 같은 방법은 상대적 거리를 학습하기에는 한계가 있다. 그러나 삼각함수를 사용할 경우 두 위치간의 관계를 위치 차이만큼 회전한 Matrix로 나타낼 수 있다. 즉, linear function으로 나타내는 것이 가능해지기 때문에, 상대적 거리를 학습하는 것에 유리하다. 또한 시퀀스의 길이가 변하더라도 (training시에 사용한 길이보다 길어도) 주파수가 다른 삼각함수 곡선을 사용하는 셈이 되므로 문제될 것이 없다.
<6> Residual Connection
Residual Connection은 ResNET에서 소개된 방법이다. 경사 소실 (gradient vanishing) 문제의 해결책으로 쓰일 수 있으며, 층이 깊을 경우 원래 입력의 raw information이 줄어든다는 점을 해결할 수 있다. Transformer의 경우 인코더와 디코더 포함 총 12개가 있지만, 각각의 sub layer를 고려했을 때, 30층 정도라 볼 수 있기 때문에, 이를 쓴 것으로 보인다.
<7> Optimizer
왼쪽 그림과 같이 어느 시점(warmup step)까지는 linear하게 증가하다가, 이후에는 inverse square root에 비례하게 감소시킨다. 초반에는 정확도가 많이 부족하므로, 학습률을 높이다가 나중에는 세밀하게 조절할 필요가 있으므로 이처럼 설정한 것을 보인다.

<8> Label Smoothing
label의 logit을 보통 one-hot vector(=hard target), 즉 정답 값이 1이고 나머지는 0인 벡터를 쓰는데 이 벡터의 단점을 보완한 방법이다. soft target라고도 부른다. 으로 표현하는데 논문에서는 a=0.1을 사용한다. 예를 들어 [0 0 1 0] 이란 벡터가 있다면 [0.025, 0.025 0.925 0.025]가 되는 셈이다. hard target을 사용할 경우 모델이 정답과 같게 하는 것에만 집중하게 되는 반면, soft target을 쓸 경우 오답도 작은 값을 남겨둠으로써 정답과 가까워지면서, 오답과도 거리가 있도록 하는 효과가 있다. 다른 논문에서는 이에 대해 target cluster를 tighter하게 하는 효과가 있다고 말하고 있다.
참고 자료:
jalammar.github.io/illustrated-transformer/
'딥러닝 > NLP' 카테고리의 다른 글
| [논문 리뷰] BERT : Bidirectional Transformer (0) | 2021.08.20 |
|---|---|
| [논문 리뷰] GPT : Generative Pre-training / OpenAI NLP (0) | 2021.03.03 |

